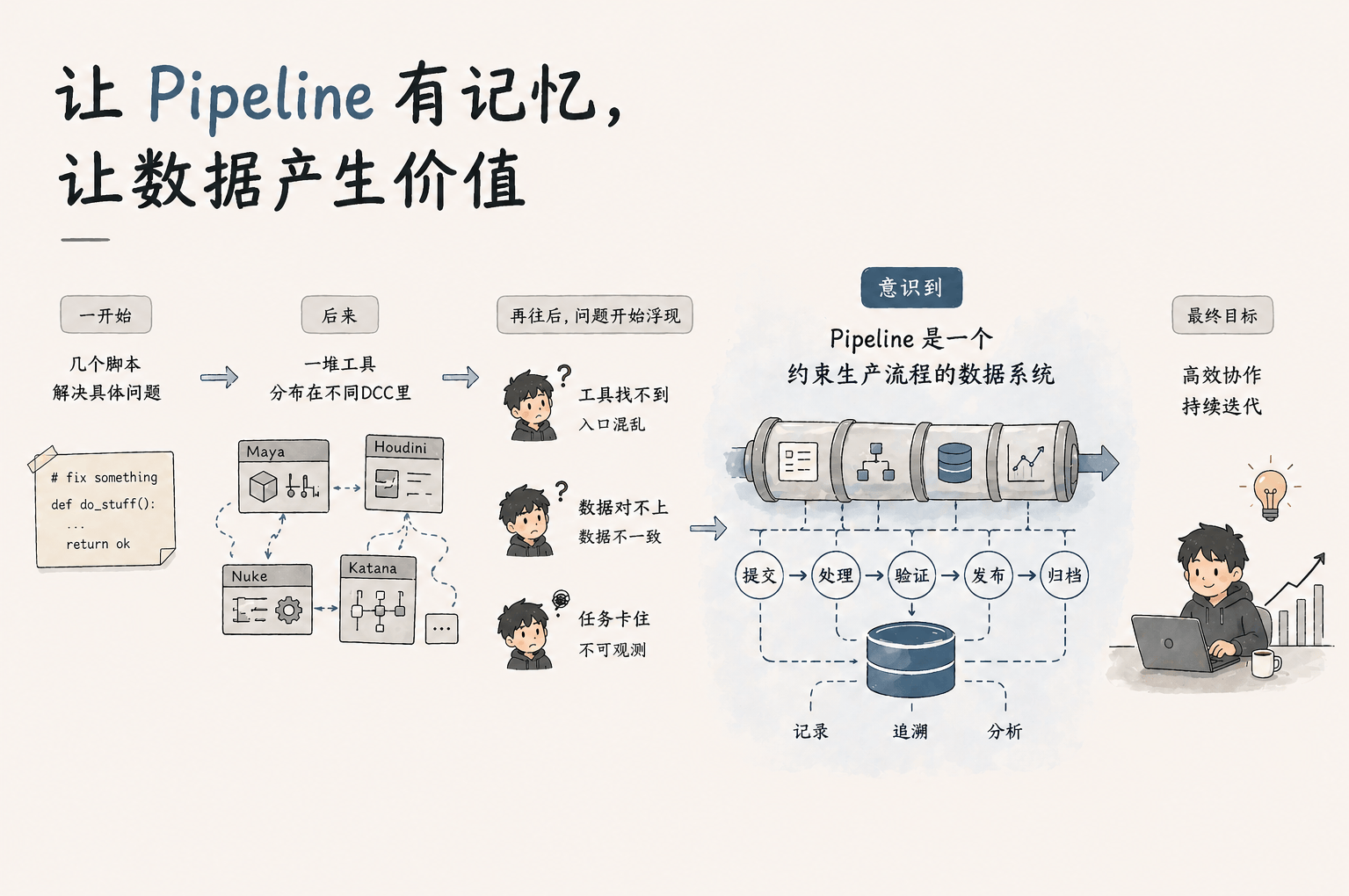
一些值得关注的 3D AI 项目分类整理
一些值得关注的 3D AI 项目分类整理
lingyun从别的网站收集整理来的一份3D相关的AI开源项目集合。
来源: https://aiartweekly.com/tools/3d/3d-animation
3D Animation
3D 动画
| 工具 | 简单说明 | 链接 |
|---|---|---|
| AnimateAnyMesh | AnimateAnyMesh 可以根据文本提示制作 3D 网格动画。 | 项目地址/Github |
| AnyTop | AnyTop 可以仅使用不同角色的骨骼结构来生成不同角色的动作。 | 项目地址/Github |
| Make-It-Animatable | Make-It-Animatable 可以在一秒内自动装配任何 3D 人形模型以实现动画。它生成高质量的混合权重和骨骼,并适用于各种 3D 格式,即使对于非标准骨骼也能确保准确性。 | 项目地址/Github |
| MagicArticulate | MagicArticulate 可以装配静态 3D 模型并使其为动画做好准备。适用于人形和非人形物体。 | 项目地址/Github |
| SMF | SMF 可以将 2D 或 3D 关键点动画转换为全身网格动画,而无需模板网格或校正关键帧。 | 项目地址/Github |
| RigAnything | RigAnything 可以通过生成关节、骨架和蒙皮权重来自动装备 3D 资源,而无需模板。它支持任何输入姿势和装备形状,速度比其他方法快 20 倍,每个形状所需时间不到 2 秒。 | 项目地址/Github |
| SplattingAvatar | SplattingAvatar 可以使用高斯 Splatting 和三角形网格几何体的组合来生成逼真的实时人类头像。它在现代 GPU 上可实现超过 300 FPS,在移动设备上可实现 30 FPS,支持详细的外观建模和各种动画技术。 | 项目地址/Github |
| X-Avatar | X-Avatar 可以捕捉数字人类的完整表现力,在远程呈现和 AR/VR 中提供逼真的体验。它使用完整的 3D 扫描或 RGB-D 数据,并在具有 35,500 个高质量帧的新数据集的支持下,在动画任务中优于其他方法。 | 项目地址/Github |
3D Avatar Generation
3D 虚拟形象生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| PERSONA | PERSONA 可以从单个图像创建个性化 3D 头像,从而实现反映主体身份的逼真动画。 | 项目地址/Github |
| D3-Human | D3-Human 可以从单个视频中重建详细的 3D 人物形象。它将衣服和身体形状分开,很好地处理遮挡,并且对于衣服转移和动画很有用。 | 项目地址/Github |
| Disco4D | Disco4D 可以通过将衣服与身体分离,从单个图像生成 4D 人体模型并制作动画。它使用扩散模型进行详细的 3D 表示,并且可以对输入图像中不可见的部分进行建模。 | 项目地址/Github |
| SOAP | SOAP 可以从单个肖像图像生成装配好的 3D 头像。 | 项目地址/Github |
| Textoon | Textoon可以根据文本描述生成Live2D格式的各种2D卡通人物。它允许实时编辑和可控外观生成,使用户可以轻松创建交互式角色。 | 项目地址/Github |
| StdGEN | StdGEN 可以在短短三分钟内从单个图像生成高质量的 3D 角色。它将角色分解为身体、衣服和头发等部分,使用基于 Transformer 的模型在 3D 动漫角色生成中取得良好的效果。 | 项目地址/Github |
| DressRecon | DressRecon 可以从单个视频创建 3D 人体模型。它可以很好地处理宽松的衣服和物体,通过将一般人体形状与特定的视频动作相结合来实现高质量的结果。 | 项目地址/Github |
| LHM | LHM 可以在几秒钟内从单个图像生成高质量、可动画的 3D 人体头像。它保留了服装几何形状和纹理等细节,无需对面部和手部进行额外处理。 | 项目地址/Github |
| Vid2Avatar-Pro | Vid2Avatar-Pro 可以从单个视频创建逼真的可动画 3D 人体头像。 | 项目地址/Github |
| DreamWaltz-G | DreamWaltz-G 可以从文本生成高质量的 3D 头像,并使用 SMPL-X 运动序列将其动画化。它通过骨架引导分数蒸馏提高了头像的一致性,对于人类视频重演和创建具有多个主题的场景非常有用。 | 项目地址/Github |
| RodinHD | RodinHD 可以从肖像图像生成高保真 3D 头像。该方法能够捕捉复杂的细节,例如发型,并且可以推广到野外肖像输入。 | 项目地址/Github |
| MeshAvatar | MeshAvatar 可以从多视图视频中生成高质量的三角形人体头像。化身可以被编辑、操纵和重新点燃。 | 项目地址/Github |
| InstructHumans | InstructHumans 可以使用文本提示编辑现有的 3D 人体纹理。它很好地保持了头像的一致性,并且可以轻松实现动画。 | 项目地址/Github |
| AiOS | AiOS可以一步估计人体姿势和形状,结合身体、手部和面部表情恢复。 | 项目地址/Github |
| SplattingAvatar | SplattingAvatar 可以使用高斯 Splatting 和三角形网格几何体的组合来生成逼真的实时人类头像。它在现代 GPU 上可实现超过 300 FPS,在移动设备上可实现 30 FPS,支持详细的外观建模和各种动画技术。 | 项目地址/Github |
| GALA | GALA 可以将单层服装 3D 人体网格转化为完整的多层 3D 资产。然后,输出可以与其他资产相结合,以创建具有任何姿势的新服装人类化身。 | 项目地址/Github |
| En3D | En3D 可以从 2D 图像生成高质量的 3D 人体头像,而无需现有资产。 | 项目地址/Github |
| Relightable and Animatable Neural Avatars from Videos | RelightableAvatar 是另一种可以从单眼视频创建可重新照明且可动画化的神经化身的方法。 | 项目地址/Github |
| ASH | ASH 可以实时渲染逼真且可动画的 3D 人体头像。 | 项目地址/Github |
| Relightable Gaussian Codec Avatars | Relightable Gaussian Codec Avatars 可以生成高质量、可重新照明的 3D 头部头像,显示发丝和毛孔等精细细节。它们在不同的照明条件下都能很好地实时工作,并针对消费者 VR 耳机进行了优化。 | 项目地址/Github |
| Head360 | Head360可以生成参数化3D全头模型,您可以从任何角度查看!它只需一张图片即可工作,让您快速改变表情和发型。 | 项目地址/Github |
| TECA | TECA 可以根据文本描述生成逼真的 3D 头像。它将面部和身体的传统 3D 网格与头发和衣服的神经辐射场 (NeRF) 相结合,从而实现高质量、可编辑的化身以及它们之间的轻松特征传输。 | 项目地址/Github |
| X-Avatar | X-Avatar 可以捕捉数字人类的完整表现力,在远程呈现和 AR/VR 中提供逼真的体验。它使用完整的 3D 扫描或 RGB-D 数据,并在具有 35,500 个高质量帧的新数据集的支持下,在动画任务中优于其他方法。 | 项目地址/Github |
| EVA3D | EVA3D 可以从 2D 图像集合生成高质量的 3D 人体模型。它使用一种称为组合 NeRF 的方法来处理详细的形状和纹理,并通过姿势引导采样来改进学习。 | Github |
3D Editing
3D 编辑
| 工具 | 简单说明 | 链接 |
|---|---|---|
| WeatherEdit | WeatherEdit 可以在 3D 场景中生成逼真的天气效果,并控制类型和严重程度。它对天气粒子使用动态 4D 高斯场,并确保图像之间的一致性,使其成为恶劣天气下自动驾驶等模拟的理想选择。 | 项目地址/Github |
| Lite2Relight | Lite2Relight 可以重新照亮人物肖像,同时保持 3D 一致性和身份。 | 项目地址/Github |
| MeshPad | MeshPad 可以从 2D 草图创建和编辑 3D 网格。用户可以通过简单的草图更改轻松添加或删除网格零件。 | 项目地址/Github |
| OmniPart | OmniPart 可以通过规划结构然后创建它们,从单个图像生成 3D 对象。 | 项目地址/Github |
| WIR3D | WIR3D 可以抽象 3D 形状,以便轻松更改形状。 | 项目地址/Github |
| SceneFactor | SceneFactor 使用中间 3D 语义图从文本生成 3D 场景。可以编辑该贴图以添加、删除、调整大小和替换对象,从而轻松重新生成最终 3D 场景。 | 项目地址/Github |
| ReStyle3D | ReStyle3D 可以从不同角度将风格图像的外观转移到现实世界场景。它保持结构和细节完整,非常适合室内设计和虚拟舞台。 | 项目地址/Github |
| ObjectCarver | ObjectCarver 只需用户输入点击即可从单个视图中分割、重建和分离 3D 对象,从而无需分割蒙版。 | 项目地址/Github |
| LIFe-GoM | LIFe-GoM 可以在 1 秒内从稀疏的多视图图像创建可动画的 3D 人体头像。它以每秒 95.1 帧的速度渲染高质量图像。 | 项目地址/Github |
| Hunyuan3D 2.0 | Hunyuan3D 2.0可以生成高分辨率纹理3D资源。它允许用户高效地创建详细的 3D 模型并为其制作动画,与以前的模型相比,几何细节和纹理质量得到了改进。 | 项目地址/Github |
| GaussianDreamerPro | GaussianDreamerPro 可以从文本生成 3D 高斯资产,这些资产可以无缝集成到下游操作管道中,例如动画、合成和模拟。 | 项目地址/Github |
| Coin3D | Coin3D 可以从基本输入形状生成和编辑 3D 资产。与 ControlNet 类似,这可以在几秒钟内实现精确的零件编辑和响应式 3D 对象预览。 | 项目地址/Github |
| Digital Salon | Digital Salon可以根据文本描述生成详细的3D发型。它支持多达 80,000 根发丝,并允许实时模拟和交互式修饰。 | 项目地址/Github |
| Trellis 3D | Trellis 3D 可生成辐射场、3D 高斯和网格等格式的高质量 3D 资源。它支持文本和图像调节,提供灵活的输出格式选择和本地 3D 编辑功能。 | 项目地址/Github |
| Drivable 3D Gaussian Avatars | D3GA 是第一个使用高斯图实时渲染的人体 3D 可控模型。这让我们可以将自己或其他具有多摄像头设置的人变成可以动画化的高斯splat,甚至允许将化身分解成不同的布料层。 | 项目地址/Github |
| SPARK | SPARK 可以根据常规视频创建高质量的 3D 脸部头像,并实时跟踪表情和姿势。它提高了老化、面部交换和数字化妆等任务的 3D 面部重建的准确性。 | 项目地址/Github |
| GenN2N | 由于方法总是成对出现,GenN2N 是另一种 NeRF 编辑方法。它可以使用文本提示编辑场景、着色、升级和修复它们。 | 项目地址/Github |
| MagicClay | 虽然 TripoSR 可以从图像生成网格,但 MagicClay 可以编辑它们。它是一个艺术家友好的工具,允许您使用文本提示雕刻网格区域,同时保持其他区域不变。 | 项目地址/Github |
| A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis | 生成辐射场重新照明可以重新照亮在单个光源下捕获的 3D 场景。它可以真实地控制光线方向并提高视图的一致性,使其适用于具有多个对象的复杂场景。 | 项目地址/Github |
| DreamCatalyst | DreamCatalyst 可以在大约 25 分钟内编辑 NeRF 场景,或在不到 70 分钟内产生高质量的结果。 | 项目地址/Github |
| GScream | GScream 是另一种在 3D 场景中移除对象的方法。该模型使用高斯溅射来更新辐射场,并且能够保持几何一致性和纹理连贯性。 | 项目地址/Github |
| StructLDM | StructLDM 可以通过混合不同的身体部位、身份交换、本地服装编辑、3D 虚拟试穿等来生成可动画的合成人体。人工智能女朋友/男朋友肯定会成为热门话题。 | 项目地址/Github |
| LogoMotion | LogoMotion 可以将分层 PDF 文件中的徽标转换为内容感知的动画 HTML 画布动画。非常酷! | 项目地址/Github |
| DGE | DGE 是一种高斯溅射方法,可用于根据文本提示编辑 3D 对象和场景。 | 项目地址/Github |
| Make-it-Real | Make-it-Real 可以使用 GPT-4V 识别和描述材料,帮助构建详细的材料库。它将材质与 3D 对象部分对齐,并从反照率贴图创建 SVBRDF 材质,从而提高 3D 资产的真实感。 | 项目地址/Github |
| InFusion | InFusion 可以修复 3D 高斯点云以恢复丢失的 3D 点,以获得更好的视觉效果。它允许用户更改纹理并添加新对象,从而实现高质量和高效率。 | 项目地址/Github |
| InstructHumans | InstructHumans 可以使用文本提示编辑现有的 3D 人体纹理。它很好地保持了头像的一致性,并且可以轻松实现动画。 | 项目地址/Github |
| HoloDreamer | HoloDreamer 可以根据文本描述生成封闭的 3D 场景。它首先创建高质量的等距柱状全景图,然后使用 3D 高斯分布快速重建 3D 场景。 | 项目地址/Github |
| GALA | GALA 可以将单层服装 3D 人体网格转化为完整的多层 3D 资产。然后,输出可以与其他资产相结合,以创建具有任何姿势的新服装人类化身。 | 项目地址/Github |
| SIGNeRF | SIGNeRF 是一种快速、可控的 NeRF 场景编辑和场景集成对象生成的新方法。该方法能够在现有 NeRF 场景中生成新对象,或者通过代理对象放置或形状选择以可控方式编辑场景内的现有对象。 | 项目地址/Github |
| 3D Paintbrush | 3D Paintbrush 可以使用文本描述自动将纹理添加到 3D 模型上的特定区域。它可以生成详细的定位和纹理图,从而提高各种项目中的图形质量。 | 项目地址/Github |
| Head360 | Head360可以生成参数化3D全头模型,您可以从任何角度查看!它只需一张图片即可工作,让您快速改变表情和发型。 | 项目地址/Github |
| Progressive3D | Progressive3D 可以通过将过程分解为更小的编辑步骤,根据复杂的提示生成详细的 3D 内容。它让用户专注于特定区域进行编辑,并通过突出显示含义差异来改进结果。 | 项目地址/Github |
| Generative Repainting | 生成重绘可以使用文本提示来绘制 3D 资源。它使用预训练的 2D 扩散模型和 3D 神经辐射场来为各种 3D 形状创建高质量纹理。 | 项目地址/Github |
| TECA | TECA 可以根据文本描述生成逼真的 3D 头像。它将面部和身体的传统 3D 网格与头发和衣服的神经辐射场 (NeRF) 相结合,从而实现高质量、可编辑的化身以及它们之间的轻松特征传输。 | 项目地址/Github |
| Sin3DM | Sin3DM 可以从单个纹理形状生成高质量的 3D 对象变体。它使用扩散模型来了解对象的各个部分如何组合在一起,从而实现重定向、覆盖和本地编辑。 | 项目地址/Github |
| Vox-E | Vox-E 可以根据文本提示更改 3D 对象的形状和外观来编辑 3D 对象。它使用一种特殊的方法来保持编辑后的对象与原始对象的连接,从而允许进行大大小小的更改。 | 项目地址/Github |
| TEXTure | TEXTURE 可以使用文本提示生成和编辑 3D 形状的无缝纹理。它使用深度到图像扩散模型从不同角度创建一致的纹理,并允许根据用户输入进行细化。 | 项目地址/Github |
| RecolorNeRF | RecolorNeRF 可以改变 3D 场景中的颜色,同时保持视图一致。它将场景分解为纯色图层,可以轻松进行颜色调整并产生比其他方法更好的逼真结果。 | 项目地址/Github |
3D Hair Generation
3D 头发生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| UniHair | UniHair 可以从单视图肖像创建 3D 头发模型,处理编织和非编织风格。它使用大型数据集和先进技术来准确捕捉复杂的发型并很好地推广到真实图像。 | 项目地址/Github |
| Perm | 烫发可以生成和操纵 3D 发型。它支持 3D 头发参数化、发型插值、单视图头发重建和头发条件图像生成等应用。 | 项目地址/Github |
| MonoHair | MonoHair 可以从单个视频创建高质量的 3D 头发。它采用两步过程进行详细的头发重建,并在各种发型中实现最佳性能。 | 项目地址/Github |
| HAAR | HAAR 可以根据文本提示生成逼真的 3D 发型。它使用 3D 发丝创建详细的头发结构,并允许基于物理的渲染和模拟。 | 项目地址/Github |
3D Mesh Generation
3D 网格生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| BLADE | BLADE 可以通过估计透视投影参数从单个图像中恢复 3D 人体网格。 | 项目地址/Github |
| MeshPad | MeshPad 可以从 2D 草图创建和编辑 3D 网格。用户可以通过简单的草图更改轻松添加或删除网格零件。 | 项目地址/Github |
| MeshMosaic | MeshMosaic 可以生成包含超过 100,000 个三角形的高分辨率 3D 网格。它将形状分解为更小的块,以获得更好的细节和准确性,优于通常只能处理 8,000 个面部的其他方法。 | 项目地址/Github |
| MeshArt | MeshArt 可以生成具有清晰形状的 3D 网格。 | 项目地址/Github |
| Hi3DGen | Hi3DGen 可以从 2D 图像生成高质量的 3D 形状。它使用三步过程来准确捕捉精细细节,在真实感方面优于其他方法。 | 项目地址/Github |
| Pixel3DMM | Pixel3DMM 可以从单个 RGB 图像重建 3D 人脸。 | 项目地址/Github |
| SparseFlex | SparseFlex 可以生成具有复杂形状和表面的高分辨率 3D 网格。 | 项目地址/Github |
| DeepMesh | DeepMesh 可以从点云和图像生成高质量的 3D 网格。 | 项目地址/Github |
| TreeMeshGPT | TreeMeshGPT 可以使用自回归树排序从点云生成详细的 3D 网格。该技术可实现更好的网格细节,并在处理过程中将数据大小减少 22%。 | Github |
| PRM | PRM 可以使用光度立体技术从单个图像创建高质量的 3D 网格。它可以改善细节并处理照明和材质的变化,从而实现重新照明和材质编辑等功能。 | 项目地址/Github |
| GarVerseLOD | GarVerseLOD 可以从单个图像生成高质量的 3D 服装网格。它可以很好地处理复杂的布料运动和姿势,使用包含 6,000 个服装模型的大型数据集来提高准确性。 | 项目地址/Github |
| SPARK | SPARK 可以根据常规视频创建高质量的 3D 脸部头像,并实时跟踪表情和姿势。它提高了老化、面部交换和数字化妆等任务的 3D 面部重建的准确性。 | 项目地址/Github |
| BPT | 通过压缩标记化缩放网格生成可以生成具有超过 8,000 个面的高质量网格。 | 项目地址/Github |
| MeshAnything V2 | MeshAnything V2 可以从点云、网格、图像、文本等生成 3D 网格。 | 项目地址/Github |
| XHand | XHand 可以实时生成高保真手部形状和纹理,为虚拟环境提供富有表现力的手部头像。 | 项目地址/Github |
| MeshAnything | MeshAnything 可以将任何 3D 表示形式的 3D 资源转换为网格。这可用于增强各种 3D 资产制作方法,并显着提高存储、渲染和模拟效率。 | 项目地址/Github |
| Dynamic Gaussians Mesh | DG-Mesh 能够从单个视频重建高质量且时间一致的 3D 网格。该方法还能够随着时间的推移跟踪网格顶点,从而能够对动态对象进行纹理编辑。 | 项目地址/Github |
| MonoHair | MonoHair 可以从单个视频创建高质量的 3D 头发。它采用两步过程进行详细的头发重建,并在各种发型中实现最佳性能。 | 项目地址/Github |
| AiOS | AiOS可以一步估计人体姿势和形状,结合身体、手部和面部表情恢复。 | 项目地址/Github |
| DreamGaussian | DreamGaussian 可以在短短 2 分钟内从单视图图像生成高质量的纹理网格。它使用 3D 高斯泼溅模型进行快速网格提取和纹理细化。 | 项目地址/Github |
| Shap-E | Shap-E 可以通过为隐式函数生成参数来生成复杂的 3D 资产。它可以创建纹理网格和神经辐射场,并且比 Point-E 模型运行速度更快、质量更好。 | 项目地址/Github |
3D Motion Capture
3D 动作捕捉
| 工具 | 简单说明 | 链接 |
|---|---|---|
| EventEgo3D++ | EventEgo3D++ 可以使用带有鱼眼镜头的单目事件相机捕获 3D 人体运动。它在弱光和高速条件下运行良好,与基于 RGB 的方法相比,能够以 140Hz 的频率提供高精度的实时 3D 姿态更新。 | 项目地址/Github |
3D Motion Generation
3D 动作生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| GestureHYDRA | GestureHYDRA 可以为语音应用生成清晰的手势。 | 项目地址/Github |
| Motion-2-to-3 | Motion-2-to-3 可以使用视频中的 2D 动作数据根据文本提示生成逼真的 3D 人体动作。它通过使用多视图扩散模型预测一致的关节运动和根部动力学来提高运动多样性和效率。 | 项目地址/Github |
| MotionStreamer | MotionStreamer可以根据文本提示生成人体动作,并支持动作合成和较长的动作生成。还有一个 Blender 插件。 | 项目地址/Github |
| Animate3D | Animate3D 可以为任何静态多视图 3D 模型制作动画。 | 项目地址/Github |
| Expressive Whole-Body 3D Gaussian Avatar | ExAvatar 可以通过单眼短视频制作富有表现力的全身 3D 人体头像。它在此过程中捕捉面部表情、手部动作和身体姿势。 | 项目地址/Github |
| From Audio to Photoreal Embodiment | Audio2Photoreal 可以生成全身逼真的化身,并根据二元交互的对话动态做出手势。给定语音音频,该模型能够输出个人多种可能的手势运动,包括面部、身体和手。结果是高度逼真的化身,可以表达手势中的关键细微差别,例如冷笑和傻笑。 | 项目地址/Github |
3D Object Detection
3D 物体检测
| 工具 | 简单说明 | 链接 |
|---|---|---|
| SpatialTrackerV2 | SpatialTrackerV2 可以使用单个系统进行点跟踪、深度和摄像机位置来跟踪视频中的 3D 点。 | 项目地址/Github |
| CoMotion | CoMotion 仅使用一台摄像头即可检测和跟踪多人的 3D 姿势。它在拥挤的地方运行良好,并且可以高精度地跟踪一段时间内的运动情况。 | Github |
| DELTA | DELTA 可以高精度地跟踪单摄像头视频中的密集 3D 运动。它使用先进的技术来加速该过程,使其比旧方法快 8 倍以上,同时保持像素级精度。 | 项目地址/Github |
| Dessie | Dessie 可以根据单幅图像估计马的 3D 形状和姿势。它也适用于斑马和牛等其他大型动物。 | 项目地址/Github |
| Find Any Part in 3D | Find3D 可以根据文本查询分割 3D 对象的各个部分。 | 项目地址/Github |
| EgoAllo | EgoAllo 可以使用头戴式设备的图像来估计 3D 人体姿势、高度和手部参数。 | 项目地址/Github |
| CityGaussian | CityGaussian 可以使用分而治之的训练方法和细节层次策略实时渲染大规模 3D 场景。它在 A100 GPU 上以平均 36 FPS 的速度实现高质量渲染。 | 项目地址/Github |
| WildGaussians | WildGaussians 是一种新的 3D 高斯喷射方法,可以处理遮挡和外观变化。该方法能够实现实时渲染速度,并且能够比其他方法更好地处理野外数据。 | 项目地址/Github |
| Reconstructing Hand-Held Objects in 3D | [MCC-Hand-Object (MCC-HO)] 可以从单个 RGB 图像和 3D 手模型重建手持物体的 3D 形状。它使用检索增强重建 (RAR) 和 GPT-4(V) 将 3D 模型与对象的形状相匹配,从而在各种数据集上实现最佳性能。 | 项目地址/Github |
| 3D Gaussian Splatting for Real-Time Radiance Field Rendering | 3D Gaussian Splatting 可以以 1080p 分辨率、每秒超过 30 帧的速度实时创建高质量 3D 场景。它使用 3D 高斯进行高效的场景表示和快速渲染方法,在保持出色的视觉质量的同时实现有竞争力的训练时间。 | 项目地址/Github |
| Seeing the World through Your Eyes | 据说我们的眼睛容纳着宇宙。当谈到《通过你的眼睛看世界》论文中讨论的方法时,他们至少拥有一个3D场景。论文中讨论的方法能够使用包含眼睛反射的肖像图像重建超出相机视线的 3D 场景。 | 项目地址/Github |
| Robust Dynamic Radiance Fields | 鲁棒动态辐射场可以估计静态和动态辐射场以及相机设置。它改进了困难视频的视图合成,实现了比当前顶级方法更好的质量和准确性。 | 项目地址/Github |
3D Object Generation 3D Editing 3D Relighting
3D 物体生成、3D 编辑、3D 重打光
| 工具 | 简单说明 | 链接 |
|---|---|---|
| Subsurface Scattering for 3D Gaussian Splatting | 高斯散射的次表面散射可以实时渲染和重新照亮半透明物体。它允许进行详细的材质编辑,并在 150 FPS 左右实现高视觉质量。 | 项目地址/Github |
3D Object Generation Motion Generation
3D 物体生成、动作生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| Synthesizing Moving People with 3D Control | 3DHM 可以通过 3D 摄像机控制单个图像和给定的目标视频运动序列来制作人物动画。 | 项目地址/Github |
3D Object Generation
3D 物体生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| GeoSAM2 | GeoSAM2 可以使用 2D 提示将 3D 网格分割成多个部分。 | 项目地址/Github |
| Lite2Relight | Lite2Relight 可以重新照亮人物肖像,同时保持 3D 一致性和身份。 | 项目地址/Github |
| VertexRegen | VertexRegen 可以通过顶点分割反转边缘折叠过程,生成具有不同细节级别的 3D 网格。 | 项目地址/Github |
| Assembler | Assembler 可以根据零件网格和参考图像重建完整的 3D 对象。 | 项目地址/Github |
| StyleSculptor | StyleSculptor 可以从内容图像和样式图像生成 3D 资源,无需额外培训。 | 项目地址/Github |
| OmniPart | OmniPart 可以通过规划结构然后创建它们,从单个图像生成 3D 对象。 | 项目地址/Github |
| SewingLDM | SewingLDM 可以使用文本提示、身体形状和服装草图生成复杂的缝纫图案。它允许进行详细的定制,并显着改进服装的设计以适应不同的体型。 | 项目地址/Github |
| DPoser-X | DPoser-X 可以使用基于扩散的模型生成并完成 3D 全身人体姿势。 | 项目地址/Github |
| Symmetry Strikes Back | Reflect3D 可以从单个 RGB 图像中检测 3D 反射对称性并改进 3D 生成。 | 项目地址/Github |
| PhysX | PhysX 可以生成具有详细物理属性的 3D 资产,在五个关键领域标记资产:规模、材料、可供性、运动学和功能。 | 项目地址/Github |
| GeoSplatting | GeoSplatting 可以捕获详细的 3D 形状以及逼真的材质和照明。 | 项目地址/Github |
| Hunyuan3D 2.1 | Hunyuan3D 2.1可以通过形状生成和纹理合成从图像生成高质量的3D资产。 | Github |
| PartPacker | PartPacker 可以从单个图像生成具有许多有意义的部分的高质量 3D 对象。 | 项目地址/Github |
| MeshArt | MeshArt 可以生成具有清晰形状的 3D 网格。 | 项目地址/Github |
| ObjectCarver | ObjectCarver 只需用户输入点击即可从单个视图中分割、重建和分离 3D 对象,从而无需分割蒙版。 | 项目地址/Github |
| Generating Physically Stable and Buildable LEGO Designs from Text | LegoGPT 可以根据文本提示生成稳定且可搭建的乐高设计。它使用物理感知技术来确保设计对于手动组装和机器人施工来说是安全的,并且它可以创建彩色和纹理模型。 | 项目地址/Github |
| PrimitiveAnything | PrimitiveAnything 可以通过将复杂的形状分解为简单的几何部分,从 3D 模型、文本和图像生成高质量的 3D 形状。它使用形状调节的原始变压器来确保形状保持准确和多样化。 | 项目地址/Github |
| DiffLocks | DiffLocks 可以在 3 秒内从单个图像生成详细的 3D 头发几何形状。 | 项目地址/Github |
| HoloPart | HoloPart 可以将 3D 形状分解为完整且有意义的部分,即使它们是隐藏的。它还支持众多下游应用程序,例如几何编辑、几何处理、材质编辑和动画。 | 项目地址/Github |
| AniSDF | AniSDF 可以通过改进的表面几何结构重建高质量的 3D 形状。它可以处理复杂、发光、反射以及模糊的物体。 | 项目地址/Github |
| Pixel3DMM | Pixel3DMM 可以从单个 RGB 图像重建 3D 人脸。 | 项目地址/Github |
| GARF | GARF 可以从现实世界的断裂零件中重新组装 3D 对象。 | 项目地址/Github |
| HORT | HORT 可以仅通过一张照片创建手持物体的详细 3D 点云。 | 项目地址/Github |
| LVSM | LVSM 可以从一些输入图像生成对象和场景的高质量 3D 视图。 | 项目地址/Github |
| StdGEN | StdGEN 可以在短短三分钟内从单个图像生成高质量的 3D 角色。它将角色分解为身体、衣服和头发等部分,使用基于 Transformer 的模型在 3D 动漫角色生成中取得良好的效果。 | 项目地址/Github |
| 3D-GPT | 到目前为止,还很难想象人工智能代理的好处。我们从该领域看到的大部分内容都集中在 NPC 模拟或解决基于文本的目标。 3D-GPT 是一种新框架,它利用 LLM 进行指令驱动的 3D 建模,将 3D 建模任务分解为可管理的部分,以按程序生成 3D 场景。我最近开始深入研究 Blender,我祈祷它有一天能开源。 | 项目地址/Github |
| FreeTimeGS | FreeTimeGS 可以使用出现在不同时间和地点的高斯基元实时重建动态 3D 场景。 | 项目地址/Github |
| LIFe-GoM | LIFe-GoM 可以在 1 秒内从稀疏的多视图图像创建可动画的 3D 人体头像。它以每秒 95.1 帧的速度渲染高质量图像。 | 项目地址/Github |
| Controlling Space and Time with Diffusion Models | Google DeepMind 一直在研究 4DiM,这是一种用于 4D 新颖视图合成的级联扩散模型。它可以根据单个图像以及一组相机姿势和时间戳生成具有时间动态的 3D 场景。 | 项目地址/Github |
| Dora | Dora 可以从图像生成 3D 资源,这些资源可以在现代 3D 引擎(例如 Unity 3D)中实时进行基于扩散的角色控制。 | 项目地址/Github |
| OmniPhysGS | OmniPhysGS 可以通过使用本构 3D 高斯对对象进行建模来生成逼真的 3D 动态场景。 | 项目地址/Github |
| Hunyuan3D 2.0 | Hunyuan3D 2.0可以生成高分辨率纹理3D资源。它允许用户高效地创建详细的 3D 模型并为其制作动画,与以前的模型相比,几何细节和纹理质量得到了改进。 | 项目地址/Github |
| GaussianDreamerPro | GaussianDreamerPro 可以从文本生成 3D 高斯资产,这些资产可以无缝集成到下游操作管道中,例如动画、合成和模拟。 | 项目地址/Github |
| Coin3D | Coin3D 可以从基本输入形状生成和编辑 3D 资产。与 ControlNet 类似,这可以在几秒钟内实现精确的零件编辑和响应式 3D 对象预览。 | 项目地址/Github |
| Digital Salon | Digital Salon可以根据文本描述生成详细的3D发型。它支持多达 80,000 根发丝,并允许实时模拟和交互式修饰。 | 项目地址/Github |
| REACTO | REACTO 可以通过从单个视频中捕捉具有灵活变形的物体的运动和形状来重建铰接的 3D 物体。 | 项目地址/Github |
| Trellis 3D | Trellis 3D 可生成辐射场、3D 高斯和网格等格式的高质量 3D 资源。它支持文本和图像调节,提供灵活的输出格式选择和本地 3D 编辑功能。 | 项目地址/Github |
| Dessie | Dessie 可以根据单幅图像估计马的 3D 形状和姿势。它也适用于斑马和牛等其他大型动物。 | 项目地址/Github |
| L4GM | L4GM 是一种 4D 大型重建模型,可以将单视图视频转换为动画 3D 对象。 | 项目地址/Github |
| Drivable 3D Gaussian Avatars | D3GA 是第一个使用高斯图实时渲染的人体 3D 可控模型。这让我们可以将自己或其他具有多摄像头设置的人变成可以动画化的高斯splat,甚至允许将化身分解成不同的布料层。 | 项目地址/Github |
| GarVerseLOD | GarVerseLOD 可以从单个图像生成高质量的 3D 服装网格。它可以很好地处理复杂的布料运动和姿势,使用包含 6,000 个服装模型的大型数据集来提高准确性。 | 项目地址/Github |
| UniHair | UniHair 可以从单视图肖像创建 3D 头发模型,处理编织和非编织风格。它使用大型数据集和先进技术来准确捕捉复杂的发型并很好地推广到真实图像。 | 项目地址/Github |
| GaussianAnything | GaussianAnything 可以从单个图像或文本提示生成高质量的 3D 对象。它使用变分自动编码器和级联潜在扩散模型来进行有效的 3D 编辑。 | 项目地址/Github |
| GarmentDreamer | GarmentDreamer 可以根据文本提示生成可穿戴、可模拟的 3D 服装网格。该方法能够生成各种几何和纹理细节,从而可以创建各种不同的服装。 | 项目地址/Github |
| SPARK | SPARK 可以根据常规视频创建高质量的 3D 脸部头像,并实时跟踪表情和姿势。它提高了老化、面部交换和数字化妆等任务的 3D 面部重建的准确性。 | 项目地址/Github |
| No Pose, No Problem | NoPoSplat 可以从多视图重建 3D 高斯场景。它实现了实时重建和高质量图像,特别是当输入图像很少时。 | 项目地址/Github |
| SphereHead | GAN 还没有消亡。 SphereHead 可从各个角度生成稳定且高质量的 3D 全头人脸,与以前的方法相比,伪影明显减少。迄今为止我见过的最好的一个。 | 项目地址/Github |
| HeadStudio | HeadStudio 是另一种文本转 3D 头像模型,可以生成可动画化的头部头像。该方法能够生成表情变形平滑、实时渲染的高保真头像。 | 项目地址/Github |
| CRM | 感觉我们现在每周都会获得一种图像转 3D 方法。 CRM 是另一种可以从单个图像生成 3D 对象的软件。它能够在短短 10 秒内创建具有可交互表面的高保真纹理网格。结果令人惊叹! | 项目地址/Github |
| Animate3D | Animate3D 可以为任何静态多视图 3D 模型制作动画。 | 项目地址/Github |
| AvatarGO | AvatarGO 可以从文本生成 4D 人机交互场景。它使用 LLM 引导的接触重定向来实现准确的空间关系,并通过对应感知运动优化确保流畅的动画。 | 项目地址/Github |
| GenN2N | 由于方法总是成对出现,GenN2N 是另一种 NeRF 编辑方法。它可以使用文本提示编辑场景、着色、升级和修复它们。 | 项目地址/Github |
| MagicClay | 虽然 TripoSR 可以从图像生成网格,但 MagicClay 可以编辑它们。它是一个艺术家友好的工具,允许您使用文本提示雕刻网格区域,同时保持其他区域不变。 | 项目地址/Github |
| A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis | 生成辐射场重新照明可以重新照亮在单个光源下捕获的 3D 场景。它可以真实地控制光线方向并提高视图的一致性,使其适用于具有多个对象的复杂场景。 | 项目地址/Github |
| GScream | GScream 是另一种在 3D 场景中移除对象的方法。该模型使用高斯溅射来更新辐射场,并且能够保持几何一致性和纹理连贯性。 | 项目地址/Github |
| GIC | 用于物理属性识别和模拟的高斯信息连续体可以从高斯点集恢复 3D 对象并模拟其物理属性。 | 项目地址/Github |
| StructLDM | StructLDM 可以通过混合不同的身体部位、身份交换、本地服装编辑、3D 虚拟试穿等来生成可动画的合成人体。人工智能女朋友/男朋友肯定会成为热门话题。 | 项目地址/Github |
| TeFF | TeFF 是一种与 SphereHead 类似的方法,该方法不仅支持人脸,还可以从单个图像的 360 度视图重建 3D 对象。 | 项目地址/Github |
| 3D-Fauna | 3D-Fauna 能够以前馈方式将四足动物的单个图像转换为铰接的、有纹理的 3D 网格,为动画和渲染做好准备。 | 项目地址/Github |
| WiLoR | WiLoR 可以根据单张图像实时定位和重建多只手。它使用包含超过 200 万张手部图像的大型数据集,实现高精度的平滑 3D 手部跟踪。 | 项目地址/Github |
| PhysAvatar | PhysAvatar 可以将多视图视频转换为穿着宽松衣服的高质量 3D 头像。整个事情可以动画化并很好地概括为看不见的运动和照明条件。 | 项目地址/Github |
| 3DTopia-XL | 3DTopia-XL 可以在短短 5 秒内从文本或图像输入生成高质量的 3D PBR 资源。 | 项目地址/Github |
| Expressive Whole-Body 3D Gaussian Avatar | ExAvatar 可以通过单眼短视频制作富有表现力的全身 3D 人体头像。它在此过程中捕捉面部表情、手部动作和身体姿势。 | 项目地址/Github |
| DreamBeast | DreamBeast 可以生成具有不同部位的独特 3D 动物资产。它使用 Stable Diffusion 3 中的方法从各种摄像机视图快速创建详细的零件亲和图,从而提高质量,同时节省计算能力。 | 项目地址/Github |
| DrawingSpinUp | DrawingSpinUp 可以将单个 2D 绘图中的 3D 角色制作成动画。它删除了不必要的线条,并使用基于骨架的算法来允许角色旋转、跳跃和跳舞。 | 项目地址/Github |
| DreamHOI | DreamHOI 可以通过设置蒙皮人体模型来根据文本描述与物体进行交互,从而生成逼真的 3D 人与物体交互 (HOI)。它使用文本到图像的扩散模型来创建多样化的交互,而不需要大型数据集。 | 项目地址/Github |
| LogoMotion | LogoMotion 可以将分层 PDF 文件中的徽标转换为内容感知的动画 HTML 画布动画。非常酷! | 项目地址/Github |
| RigAnything | RigAnything 可以通过生成关节、骨架和蒙皮权重来自动装备 3D 资源,而无需模板。它支持任何输入姿势和装备形状,速度比其他方法快 20 倍,每个形状所需时间不到 2 秒。 | 项目地址/Github |
| SparseCraft | SparseCraft 可以仅根据三张彩色图像重建 3D 形状和外观。它使用有符号距离函数 (SDF) 和辐射场,无需预训练模型即可实现 10 分钟以内的快速训练时间。 | 项目地址/Github |
| DiffComplete | DiffComplete 可以使用基于扩散的方法从不完整的扫描中完成 3D 形状。 | 项目地址/Github |
| Interactive3D | Interactive3D可以生成用户可以轻松修改的高质量3D对象。它允许添加和删除零件、拖动对象以及更改形状。 | 项目地址/Github |
| ClickDiff | ClickDiff 可以为 3D 对象生成可控的抓取。它采用双生成框架,根据用户指定的或算法预测的接触图来生成真实的抓握。 | Github |
| SV4D | SV4D 可以从单个视频生成动态 3D 内容。它确保新视图在多个帧之间保持一致,并在视频合成中实现高质量的结果。 | 项目地址/Github |
| DreamCar | DreamCar 可以通过少量图像或单图像输入重建 3D 汽车模型。它使用分数蒸馏采样和姿势优化来增强纹理对齐和整体模型质量,显着优于现有方法。 | 项目地址/Github |
| Generating 3D House Wireframes with Semantics | 3DWire 可以从文本生成 3D 房屋线框!线框可以轻松分割成不同的组件,例如墙壁、屋顶和房间,反映形状的语义本质。 | 项目地址/Github |
| An Object is Worth 64x64 Pixels | 一个对象值得 64x64 像素可以从 64x64 像素图像生成 3D 模型!它可以创建具有良好形状和颜色的逼真对象,以及更复杂的方法。 | 项目地址/Github |
| GeneFace | GeneFace 可以从任何语音音频生成高质量的 3D 人脸视频。它解决了头躯干分离问题,并提供比早期方法更好的唇形同步和图像质量。 | 项目地址/Github |
| Fast and Uncertainty-Aware SVBRDF Recovery from Multi-View Capture using Frequency Domain Analysis | BRDF-Uncertainty 可以在几秒钟内根据物体的几何形状和照明环境估计其表面材料的属性。 | 项目地址/Github |
| Portrait3D | Portrait3D 可以从单个野外肖像图像生成具有精确几何形状和纹理的高质量 3D 头部。 | 项目地址/Github |
| MeshAnything | MeshAnything 可以将任何 3D 表示形式的 3D 资源转换为网格。这可用于增强各种 3D 资产制作方法,并显着提高存储、渲染和模拟效率。 | 项目地址/Github |
| MagicPose4D | MagicPose4D 可以从文本或图像生成 3D 对象,并从视频或网格序列中的对象和角色传输精确的运动和轨迹。 | 项目地址/Github |
| RemoCap | RemoCap 可以根据运动序列重建 3D 人体。它能够以更高的保真度捕捉被遮挡的身体部位,从而减少模型穿透和运动扭曲。 | 项目地址/Github |
| NOVA-3D | NOVA-3D 可以从不重叠的正面和背面视图生成 3D 动漫角色。 | 项目地址/Github |
| DreamScene4D | DreamScene4D 可以从单个视频生成动态 4D 场景。它跟踪对象运动并处理复杂的运动,通过将 3D 路径转换为 2D 来实现精确的 2D 点跟踪。 | 项目地址/Github |
| X-Oscar | X-Oscar可以根据文本提示生成高质量的3D头像。它对几何、纹理和动画采用分步流程,同时通过先进技术解决低质量和过饱和等问题。 | 项目地址/Github |
| Invisible Stitch | Invisible Stitch 可以修复 3D 场景中缺失的深度信息,从而提高几何连贯性并使帧之间的过渡更加平滑。 | 项目地址/Github |
| TokenHMR | 在姿势重建方面,我们有 TokenHMR,它可以从单个图像中提取人体姿势和形状。 | 项目地址/Github |
| PhysDreamer | PhysDreamer 是一种基于物理的方法,使您能够在虚拟 3D 环境中戳、推、拉和投掷物体,它们会以物理上合理的方式做出反应。 | 项目地址/Github |
| InFusion | InFusion 可以修复 3D 高斯点云以恢复丢失的 3D 点,以获得更好的视觉效果。它允许用户更改纹理并添加新对象,从而实现高质量和高效率。 | 项目地址/Github |
| in2IN | in2IN 是一种动作生成模型,它考虑了整体交互的文本描述和每个相关人员的个人动作描述。这增强了动作多样性,并能够更好地控制每个人的动作,同时保持交互连贯性。 | 项目地址/Github |
| Video2Game | Video2Game 可以将现实世界的视频变成交互式游戏环境。它使用神经辐射场 (NeRF) 模块来捕获场景,使用网格模块来加快渲染速度,并使用物理模块来实现真实的对象交互。 | 项目地址/Github |
| LoopGaussian | LoopGaussian 可以将静止场景的多视图图像转换为真实的 3D 电影图像。 3D 电影图像可以从新颖的角度进行渲染,以获得自然的无缝循环视频。 | 项目地址/Github |
| Reconstructing Hand-Held Objects in 3D | [MCC-Hand-Object (MCC-HO)] 可以从单个 RGB 图像和 3D 手模型重建手持物体的 3D 形状。它使用检索增强重建 (RAR) 和 GPT-4(V) 将 3D 模型与对象的形状相匹配,从而在各种数据集上实现最佳性能。 | 项目地址/Github |
| Towards Variable and Coordinated Holistic Co-Speech Motion Generation | ProbTalk 是一种为 3D 化身生成逼真的整体语音动作的方法。该方法能够产生各种动作,并确保面部表情、手势和身体姿势之间的和谐一致。 | 项目地址/Github |
| GaussianCube | GaussianCube 是一种图像到 3D 模型,能够从多视图图像生成高质量的 3D 对象。该模型还使用 3D Gaussian Splatting,将非结构化表示转换为结构化体素网格,然后训练 3D 扩散模型来生成新对象。 | 项目地址/Github |
| Garment3DGen | Garment3DGen 可以对 2D 图像和 3D 网格服装的几何形状和纹理进行风格化!它们可以安装在参数化实体的顶部并进行模拟。可用于 VR 中的手工服装交互或将草图转换为 3D 服装。 | 项目地址/Github |
| ThemeStation | ThemeStation 可以通过几个示例生成与特定主题相匹配的各种 3D 资源。它使用两阶段过程来提高模型的质量和多样性,允许用户根据自己的文本提示创建 3D 资产。 | 项目地址/Github |
| TexDreamer | TexDreamer 可以从文本和图像生成高质量的 3D 人体纹理。它使用智能微调方法和独特的翻译模块来快速创建逼真的纹理,同时保持重要细节完整。 | 项目地址/Github |
| MVControl | 通过表面对齐高斯喷射进行可控文本到 3D 生成,可以根据文本提示创建高质量的 3D 内容。它在多视图扩散模型中使用边缘、深度、法线和涂鸦贴图,通过独特的混合引导方法增强 3D 形状。 | 项目地址/Github |
| TripoSR | TripoSR 可以在 0.5 秒内从单个图像生成高质量的 3D 网格。 | Github |
| ViewDiff | ViewDiff 是一种可以根据单个文本提示或单个姿势图像在真实环境中生成真实世界 3D 对象的高质量、多视图一致图像的方法。 | 项目地址/Github |
| GEM3D | GEM3D 是一种深度、拓扑感知的 3D 形状生成模型。该方法能够从用户建模的骨架中生成多样化且可信的 3D 形状,从而可以绘制对象的粗略结构并让模型填充其余部分。 | 项目地址/Github |
| SpaRP | SPA-RP 可以创建 3D 纹理网格并根据一张或几张 2D 图像估计相机位置。它使用 2D 扩散模型快速了解 3D 空间,在大约 20 秒内获得高质量结果。 | 项目地址/Github |
| FlashTex | FlashTex](https://flashtex.github.io) 可以根据用户提供的文本提示对输入 3D 网格进行纹理处理。这些生成的纹理也可以在不同的照明环境下正确重新照亮。 | 项目地址/Github |
| Pushing Auto-regressive Models for 3D Shape Generation at Capacity and Scalability | Argus3D 可以根据图像和文本提示生成 3D 网格,并为其生成的形状生成独特的纹理。想象一下,通过指向一个空间并使用自然语言描述您想要放置的内容来构建一个 3D 场景并用对象填充它。 | 项目地址/Github |
| Synthesizing Physically Plausible Human Motions in 3D Scenes | InterScene 是一个新颖的框架,使物理模拟的角色能够在多样化、杂乱和看不见的场景中执行长期交互任务。距离完全动态的游戏世界和模拟又近了一步。查看下面令人印象深刻的演示。 | 项目地址/Github |
| GALA | GALA 可以将单层服装 3D 人体网格转化为完整的多层 3D 资产。然后,输出可以与其他资产相结合,以创建具有任何姿势的新服装人类化身。 | 项目地址/Github |
| GARField | GARField 可以将 3D 场景分解为有意义的组。它提高了对象聚类的准确性,并允许更好地提取单个对象及其部分。 | 项目地址/Github |
| RoHM | RoHM 可以从单眼视频重建完整、可信的 3D 人体运动,并支持识别闭塞的关节!因此,基本上是类固醇的运动跟踪,但不需要昂贵的设置。 | 项目地址/Github |
| Real3D-Portrait | Real3D-Portrait 是一种一次性 3D 说话肖像生成方法。它能够生成具有自然躯干运动和可切换背景的逼真视频。 | 项目地址/Github |
| From Audio to Photoreal Embodiment | Audio2Photoreal 可以生成全身逼真的化身,并根据二元交互的对话动态做出手势。给定语音音频,该模型能够输出个人多种可能的手势运动,包括面部、身体和手。结果是高度逼真的化身,可以表达手势中的关键细微差别,例如冷笑和傻笑。 | 项目地址/Github |
| SIGNeRF | SIGNeRF 是一种快速、可控的 NeRF 场景编辑和场景集成对象生成的新方法。该方法能够在现有 NeRF 场景中生成新对象,或者通过代理对象放置或形状选择以可控方式编辑场景内的现有对象。 | 项目地址/Github |
| DreamGaussian4D | DreamGaussian4D 可以从单个图像生成动画 3D 网格。该方法能够为同一静态模型生成不同的运动,并且与其他方法相比,只需 4.5 分钟而不是几个小时。 | 项目地址/Github |
| Paint-it | Paint-it 可以根据文本描述为 3D 网格生成高保真基于物理的渲染 (PBR) 纹理图。该方法能够通过改变高动态范围(HDR)环境照明来重新照亮网格,并在测试时控制材料属性。 | 项目地址/Github |
| DreamTalk | DreamTalk 能够根据给定的文本提示生成会说话的头像。该模型能够生成多种语言的头像,还可以操纵生成视频的说话风格。 | 项目地址/Github |
| MinD-3D | MinD-3D 可以根据 fMRI 大脑信号重建高质量的 3D 对象。它使用三阶段框架来解码 3D 视觉信息,显示大脑处理和创建的对象之间的紧密联系。 | 项目地址/Github |
| Doodle Your 3D | Doodle Your 3D 可以将抽象草图变成精确的 3D 形状。该方法甚至可以通过简单地编辑草图来编辑形状。超级酷。从草图到 3D 打印现在并不遥远。 | 项目地址/Github |
| PhysGaussian | PhysGaussian 是一个模拟渲染管道,可以模拟 3D 高斯 Splats 的物理原理,同时渲染逼真的结果。该方法支持灵活的动力学、多种材料以及碰撞。 | 项目地址/Github |
| DreamCraft3D | DreamCraft3D 可以通过单个提示创建高质量的 3D 对象。它使用 2D 参考图像来指导 3D 对象的雕刻,然后通过微调的 Dreambooth 模型运行它来提高纹理保真度。 | 项目地址/Github |
| Progressive3D | Progressive3D 可以通过将过程分解为更小的编辑步骤,根据复杂的提示生成详细的 3D 内容。它让用户专注于特定区域进行编辑,并通过突出显示含义差异来改进结果。 | 项目地址/Github |
| HumanNorm | HumanNorm 是一种通过利用法线贴图来生成高质量和逼真的 3D 人体的新颖方法,可增强 3D 几何的 2D 感知。结果相当令人印象深刻,可与 PS3 游戏相媲美。 | 项目地址/Github |
| DreamGaussian | DreamGaussian 可以在短短 2 分钟内从单视图图像生成高质量的纹理网格。它使用 3D 高斯泼溅模型进行快速网格提取和纹理细化。 | 项目地址/Github |
| PlankAssembly | PlankAssembly 可以将 2D 线图从三个视图转换为 3D CAD 模型。它可以有效地处理嘈杂或不完整的输入,并使用形状程序提高准确性。 | 项目地址/Github |
| SketchMetaFace | 与 ControlNet 图像涂鸦类似,SketchMetaFace 将草图指导带入 3D 领域,并使将草图转换为 3D 面部模型成为可能。我们对这样的进展感到非常兴奋,因为这将为 3D 生成带来可控性,并使生成 3D 内容变得更容易。 | 项目地址/Github |
| NIS-SLAM | NIS-SLAM 可以从 RGB-D 帧重建高保真表面和几何结构。它还在此过程中学习 3D 一致的语义表示。 | 项目地址/Github |
| Neuralangelo | Neuralangelo 可以从 RGB 视频捕获中重建详细的 3D 表面。它使用多分辨率 3D 哈希网格和神经表面渲染,无需额外的深度输入即可实现高保真度。 | 项目地址/Github |
| Example-based Motion Synthesis via Generative Motion Matching | 现在动作捕捉很酷。但是,如果您希望 3D 角色以新颖且独特的方式移动,该怎么办? GenMM 能够从单个或几个示例序列生成各种动作。与其他方法不同,它不需要详尽的训练,并且可以在几分之一秒内创建具有复杂骨架的新动作。它还可以完成仅靠运动匹配无法完成的工作,例如运动完成、关键帧引导生成、无限循环和运动重组。 | 项目地址/Github |
| Humans in 4D | [Humans in 4D] 可以通过单个视频以 3D 形式跟踪和重建人类。它可以很好地处理不寻常的姿势和较差的可见性,使用名为 HMR 2.0 的基于变压器的网络来改进动作识别。 | 项目地址/Github |
| Sin3DM | Sin3DM 可以从单个纹理形状生成高质量的 3D 对象变体。它使用扩散模型来了解对象的各个部分如何组合在一起,从而实现重定向、覆盖和本地编辑。 | 项目地址/Github |
| Shap-E | Shap-E 可以通过为隐式函数生成参数来生成复杂的 3D 资产。它可以创建纹理网格和神经辐射场,并且比 Point-E 模型运行速度更快、质量更好。 | 项目地址/Github |
| Patch-based 3D Natural Scene Generation from a Single Example | 通过单个示例生成基于补丁的 3D 自然场景可以通过在补丁级别工作,仅从一张图像创建高质量的 3D 自然场景。它允许用户通过删除、复制或修改对象来编辑场景,同时保持逼真的形状和外观。 | 项目地址/Github |
| AvatarCraft | AvatarCraft 可以将文本提示变成高质量的 3D 人体头像。它允许用户控制头像的形状和姿势,无需重新训练即可轻松制作动画和重塑形状。 | 项目地址/Github |
| HyperDiffusion | HyperDiffusion 可以使用统一的扩散模型生成高质量的 3D 形状和 4D 网格动画。这种方法允许从单个框架创建复杂的对象和动态场景,使其具有多功能性和高效性。 | 项目地址/Github |
| PAniC-3D | PANiC-3D 可以从单视图动漫肖像中重建 3D 角色头部。它使用线填充模型和体积辐射场,取得了比以前的方法更好的结果,并为风格化重建树立了新标准。 | Github |
| MeshDiffusion | MeshDiffusion 可以使用基于分数的扩散模型和可变形四面体网格来生成逼真的 3D 网格。它非常适合从单个图像创建详细的 3D 形状,还可以添加纹理,使其可用于各种应用程序。 | 项目地址/Github |
| X-Avatar | X-Avatar 可以捕捉数字人类的完整表现力,在远程呈现和 AR/VR 中提供逼真的体验。它使用完整的 3D 扫描或 RGB-D 数据,并在具有 35,500 个高质量帧的新数据集的支持下,在动画任务中优于其他方法。 | 项目地址/Github |
| Single Motion Diffusion | 单运动扩散可以从一个输入运动序列生成逼真的动画。它允许动作扩展、风格转移和人群动画,同时使用轻量级设计有效地创建多样化的动作。 | 项目地址/Github |
| 3D Neural Field Generation using Triplane Diffusion | 使用三平面扩散的 3D 神经场生成可以从 2D 图像创建高质量的 3D 模型。它使用扩散模型将 ShapeNet 网格转变为连续占用场,在各种对象类型的 3D 生成中取得了最佳结果。 | 项目地址/Github |
| Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures | Latent-NeRF 可以通过结合文本和形状指导来生成 3D 形状和纹理。它使用潜在分数蒸馏将此指导直接应用于 3D 网格,从而在特定几何形状上实现高质量纹理。 | Github |
| InseRF | 尽管 Gaussian Splats 受到了很多人的喜爱,但 NeRF 并没有被放弃。本周我们收到了三篇不同的 NeRF 编辑论文。前两个是关于修复的。 InseRF和GO-NeRF都是将3D对象插入NeRF场景的方法。 | 项目地址/Github |
| Temporal Residual Jacobians For Rig-free Motion Transfer | [时间残差雅可比行列式] 可以将运动从一个 3D 网格转移到另一个 3D 网格,而无需装配或形状关键帧。它使用两个神经网络来预测变化,允许在不同体型之间进行真实的运动转移。 | 项目地址/Github |
3D Outpainting
3D 外绘
| 工具 | 简单说明 | 链接 |
|---|---|---|
| Sin3DM | Sin3DM 可以从单个纹理形状生成高质量的 3D 对象变体。它使用扩散模型来了解对象的各个部分如何组合在一起,从而实现重定向、覆盖和本地编辑。 | 项目地址/Github |
3D Point Tracking
3D 点追踪
| 工具 | 简单说明 | 链接 |
|---|---|---|
| TAPIP3D | TAIP3D 可以跟踪视频中的 3D 点。 | 项目地址/Github |
3D Relighting
3D 重打光
| 工具 | 简单说明 | 链接 |
|---|---|---|
| BecomingLit | BecomingLit 可以创建高分辨率的头像,可以从单个视频中重新点亮和动画化。 | 项目地址/Github |
| GeoSplatting | GeoSplatting 可以捕获详细的 3D 形状以及逼真的材质和照明。 | 项目地址/Github |
| PRM | PRM 可以使用光度立体技术从单个图像创建高质量的 3D 网格。它可以改善细节并处理照明和材质的变化,从而实现重新照明和材质编辑等功能。 | 项目地址/Github |
| GS^3 | GS^3 可以使用三重高斯泼溅过程实时重新照亮场景。它可以从多个图像实现高质量的照明和视图合成,在单个 GPU 上以 90 fps 的速度运行。 | 项目地址/Github |
3D Scene Generation 3D Object Generation
3D 场景生成、3D 物体生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| LucidDreamer | LucidDreamer 可以根据单个图像的单个文本提示生成可导航的 3D 高斯 Splat 场景。文本提示也可以链接起来以进行更多的输出控制。等不及它们也可以动画化了。 | 项目地址/Github |
3D Scene Generation
3D 场景生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| WeatherEdit | WeatherEdit 可以在 3D 场景中生成逼真的天气效果,并控制类型和严重程度。它对天气粒子使用动态 4D 高斯场,并确保图像之间的一致性,使其成为恶劣天气下自动驾驶等模拟的理想选择。 | 项目地址/Github |
| SemLayoutDiff | SemLayoutDiff 可以通过创建详细的语义地图并在考虑门窗的情况下放置家具来生成多样化的 3D 室内场景。 | 项目地址/Github |
| LongSplat | LongSplat 可以从长视频创建高质量的 3D 场景,而不需要相机位置。 | 项目地址/Github |
| Matrix-3D | Matrix-3D 可以根据单个图像或文本提示生成 3D 世界。它允许用户从任何方向探索这些环境,并支持快速和详细的场景创建。 | 项目地址/Github |
| Event-Driven Storytelling | 事件驱动的叙事可以为 3D 场景中的多个角色生成逼真的动作。它使用大型语言模型来理解复杂的交互,从而允许基于角色关系及其位置进行多样化且可扩展的行为规划。 | 项目地址/Github |
| LayoutVLM | LayoutVLM 可以根据文本指令生成 3D 布局。它提高了布局与预期设计的匹配程度,并在拥挤的空间中有效地工作。 | 项目地址/Github |
| Triangle Splatting for Real-Time Radiance Field Rendering | 在 NeRF 和高斯分布之后,我们得到了三角形分布。一种新方法,可以以超过 2,400 FPS 的速度渲染实时辐射场,分辨率为 1280x720。它将三角形表示与可微分渲染相结合,比高斯泼溅方法具有更好的视觉质量和更快的结果。 | 项目地址/Github |
| SceneFactor | SceneFactor 使用中间 3D 语义图从文本生成 3D 场景。可以编辑该贴图以添加、删除、调整大小和替换对象,从而轻松重新生成最终 3D 场景。 | 项目地址/Github |
| RenderFormer | RenderFormer 可以通过具有完整全局照明效果的三角形网格表示来渲染图像。 | 项目地址/Github |
| LT3SD | LT3SD 可以使用捕获基本形状和精细细节的方法生成大规模 3D 场景。它允许灵活的输出大小并生成高质量的场景,甚至可以完成场景中缺失的部分。 | 项目地址/Github |
| ReStyle3D | ReStyle3D 可以从不同角度将风格图像的外观转移到现实世界场景。它保持结构和细节完整,非常适合室内设计和虚拟舞台。 | 项目地址/Github |
| GPS-Gaussian+ | GPS-Gaussian+ 可以根据 2 个或更多输入图像实时渲染高分辨率 3D 场景。 | 项目地址/Github |
| PhysFlow | PhysFlow可以模拟复杂场景中的动态交互。它通过图像查询识别材质类型,并使用视频扩散和详细 4D 表示的材质点方法来增强真实感。 | 项目地址/Github |
| LVSM | LVSM 可以从一些输入图像生成对象和场景的高质量 3D 视图。 | 项目地址/Github |
| VideoScene | VideoScene 可以一步从稀疏视频视图生成 3D 场景。 | 项目地址/Github |
| GeometryCrafter | GeometryCrafter 可以从开放世界视频中恢复详细的 3D 点图。 | 项目地址/Github |
| MVGenMaster | MVGenMaster 可以使用多视图扩散模型从单个图像生成多达 100 个新视图。 | 项目地址/Github |
| 3D-GPT | 到目前为止,还很难想象人工智能代理的好处。我们从该领域看到的大部分内容都集中在 NPC 模拟或解决基于文本的目标。 3D-GPT 是一种新框架,它利用 LLM 进行指令驱动的 3D 建模,将 3D 建模任务分解为可管理的部分,以按程序生成 3D 场景。我最近开始深入研究 Blender,我祈祷它有一天能开源。 | 项目地址/Github |
| FreeTimeGS | FreeTimeGS 可以使用出现在不同时间和地点的高斯基元实时重建动态 3D 场景。 | 项目地址/Github |
| Controlling Space and Time with Diffusion Models | Google DeepMind 一直在研究 4DiM,这是一种用于 4D 新颖视图合成的级联扩散模型。它可以根据单个图像以及一组相机姿势和时间戳生成具有时间动态的 3D 场景。 | 项目地址/Github |
| LayerPano3D | LayerPano3D 可以通过将 2D 全景图分解为深度图层,根据单个文本提示生成身临其境的 3D 场景。 | 项目地址/Github |
| OmniPhysGS | OmniPhysGS 可以通过使用本构 3D 高斯对对象进行建模来生成逼真的 3D 动态场景。 | 项目地址/Github |
| Wonderland | Wonderland 可以使用摄像机引导的视频扩散模型从单个图像生成高质量的 3D 场景。它可以轻松导航和探索 3D 空间,比其他方法表现更好,尤其是对于以前从未见过的图像。 | 项目地址/Github |
| Digital Salon | Digital Salon可以根据文本描述生成详细的3D发型。它支持多达 80,000 根发丝,并允许实时模拟和交互式修饰。 | 项目地址/Github |
| DAS3R | DAS3R 可以分解场景并从视频中重建静态背景。 | 项目地址/Github |
| L4GM | L4GM 是一种 4D 大型重建模型,可以将单视图视频转换为动画 3D 对象。 | 项目地址/Github |
| SelfSplat | SelfSplat 可以从多个图像创建 3D 模型,而不需要特定的姿势。它使用自监督方法进行深度和姿态估计,从而根据真实世界的数据产生高质量的外观和几何形状。 | 项目地址/Github |
| Long-LRM | Long-LRM 可以在单个 A100 80G GPU 上仅 1.3 秒内从多达 32 个分辨率为 960x540 的输入图像重建大型 3D 场景。 | 项目地址/Github |
| CityGaussianV2 | CityGaussianV2可以从多视图RGB图像中高精度地重建大规模场景。 | 项目地址/Github |
| PF3plat | PF3plat 可以从未校准的图像集合中生成逼真的图像和准确的相机位置。 | 项目地址/Github |
| No Pose, No Problem | NoPoSplat 可以从多视图重建 3D 高斯场景。它实现了实时重建和高质量图像,特别是当输入图像很少时。 | 项目地址/Github |
| MoGe | MoGe 可以将图像和视频转换为 3D 点图。 | 项目地址/Github |
| DepthSplat | DepthSplat 通过连接高斯分布和深度估计,可以仅从少量图像中重建 3D 场景。 | 项目地址/Github |
| SceneCraft | SceneCraft 可以根据用户布局和文本描述生成详细的室内 3D 场景。它能够将 3D 布局转换为 2D 地图,生成具有不同纹理和逼真视觉效果的复杂空间。 | 项目地址/Github |
| AvatarGO | AvatarGO 可以从文本生成 4D 人机交互场景。它使用 LLM 引导的接触重定向来实现准确的空间关系,并通过对应感知运动优化确保流畅的动画。 | 项目地址/Github |
| A Diffusion Approach to Radiance Field Relighting using Multi-Illumination Synthesis | 生成辐射场重新照明可以重新照亮在单个光源下捕获的 3D 场景。它可以真实地控制光线方向并提高视图的一致性,使其适用于具有多个对象的复杂场景。 | 项目地址/Github |
| GIC | 用于物理属性识别和模拟的高斯信息连续体可以从高斯点集恢复 3D 对象并模拟其物理属性。 | 项目地址/Github |
| PhysAvatar | PhysAvatar 可以将多视图视频转换为穿着宽松衣服的高质量 3D 头像。整个事情可以动画化并很好地概括为看不见的运动和照明条件。 | 项目地址/Github |
| DreamBeast | DreamBeast 可以生成具有不同部位的独特 3D 动物资产。它使用 Stable Diffusion 3 中的方法从各种摄像机视图快速创建详细的零件亲和图,从而提高质量,同时节省计算能力。 | 项目地址/Github |
| Feature Splatting | 说到 Splats,Feature Splatting 可以使用文本提示来操纵 3D 场景中对象的外观和物理属性。 | 项目地址/Github |
| CityGaussian | CityGaussian 可以使用分而治之的训练方法和细节层次策略实时渲染大规模 3D 场景。它在 A100 GPU 上以平均 36 FPS 的速度实现高质量渲染。 | 项目地址/Github |
| Generating 3D House Wireframes with Semantics | 3DWire 可以从文本生成 3D 房屋线框!线框可以轻松分割成不同的组件,例如墙壁、屋顶和房间,反映形状的语义本质。 | 项目地址/Github |
| WildGaussians | WildGaussians 是一种新的 3D 高斯喷射方法,可以处理遮挡和外观变化。该方法能够实现实时渲染速度,并且能够比其他方法更好地处理野外数据。 | 项目地址/Github |
| LiveScene | LiveScene可以识别和控制复杂场景中的多个对象。它能够定位处于不同状态的单个对象,并能够使用自然语言对其进行控制。 | 项目地址/Github |
| Toon3D | Toon3D 可以从两个或多个卡通图画生成 3D 场景。它远非完美,但仍然很酷! | 项目地址/Github |
| DreamScene4D | DreamScene4D 可以从单个视频生成动态 4D 场景。它跟踪对象运动并处理复杂的运动,通过将 3D 路径转换为 2D 来实现精确的 2D 点跟踪。 | 项目地址/Github |
| Invisible Stitch | Invisible Stitch 可以修复 3D 场景中缺失的深度信息,从而提高几何连贯性并使帧之间的过渡更加平滑。 | 项目地址/Github |
| Video2Game | Video2Game 可以将现实世界的视频变成交互式游戏环境。它使用神经辐射场 (NeRF) 模块来捕获场景,使用网格模块来加快渲染速度,并使用物理模块来实现真实的对象交互。 | 项目地址/Github |
| LoopGaussian | LoopGaussian 可以将静止场景的多视图图像转换为真实的 3D 电影图像。 3D 电影图像可以从新颖的角度进行渲染,以获得自然的无缝循环视频。 | 项目地址/Github |
| GEM3D | GEM3D 是一种深度、拓扑感知的 3D 形状生成模型。该方法能够从用户建模的骨架中生成多样化且可信的 3D 形状,从而可以绘制对象的粗略结构并让模型填充其余部分。 | 项目地址/Github |
| Pushing Auto-regressive Models for 3D Shape Generation at Capacity and Scalability | Argus3D 可以根据图像和文本提示生成 3D 网格,并为其生成的形状生成独特的纹理。想象一下,通过指向一个空间并使用自然语言描述您想要放置的内容来构建一个 3D 场景并用对象填充它。 | 项目地址/Github |
| Spacetime Gaussian Feature Splatting for Real-Time Dynamic View Synthesis | 时空高斯特征泼溅是一种新颖的动态场景表示,能够捕获场景中的静态、动态以及瞬态内容,并可以在 RTX 4090 上以 8K 分辨率和 60 FPS 渲染它们。 | 项目地址/Github |
| PhysGaussian | PhysGaussian 是一个模拟渲染管道,可以模拟 3D 高斯 Splats 的物理原理,同时渲染逼真的结果。该方法支持灵活的动力学、多种材料以及碰撞。 | 项目地址/Github |
| DreamCraft3D | DreamCraft3D 可以通过单个提示创建高质量的 3D 对象。它使用 2D 参考图像来指导 3D 对象的雕刻,然后通过微调的 Dreambooth 模型运行它来提高纹理保真度。 | 项目地址/Github |
| 3D Gaussian Splatting for Real-Time Radiance Field Rendering | 3D Gaussian Splatting 可以以 1080p 分辨率、每秒超过 30 帧的速度实时创建高质量 3D 场景。它使用 3D 高斯进行高效的场景表示和快速渲染方法,在保持出色的视觉质量的同时实现有竞争力的训练时间。 | 项目地址/Github |
| NIS-SLAM | NIS-SLAM 可以从 RGB-D 帧重建高保真表面和几何结构。它还在此过程中学习 3D 一致的语义表示。 | 项目地址/Github |
| Seeing the World through Your Eyes | 据说我们的眼睛容纳着宇宙。当谈到《通过你的眼睛看世界》论文中讨论的方法时,他们至少拥有一个3D场景。论文中讨论的方法能够使用包含眼睛反射的肖像图像重建超出相机视线的 3D 场景。 | 项目地址/Github |
| Neuralangelo | Neuralangelo 可以从 RGB 视频捕获中重建详细的 3D 表面。它使用多分辨率 3D 哈希网格和神经表面渲染,无需额外的深度输入即可实现高保真度。 | 项目地址/Github |
| Humans in 4D | [Humans in 4D] 可以通过单个视频以 3D 形式跟踪和重建人类。它可以很好地处理不寻常的姿势和较差的可见性,使用名为 HMR 2.0 的基于变压器的网络来改进动作识别。 | 项目地址/Github |
| Patch-based 3D Natural Scene Generation from a Single Example | 通过单个示例生成基于补丁的 3D 自然场景可以通过在补丁级别工作,仅从一张图像创建高质量的 3D 自然场景。它允许用户通过删除、复制或修改对象来编辑场景,同时保持逼真的形状和外观。 | 项目地址/Github |
| HyperDiffusion | HyperDiffusion 可以使用统一的扩散模型生成高质量的 3D 形状和 4D 网格动画。这种方法允许从单个框架创建复杂的对象和动态场景,使其具有多功能性和高效性。 | 项目地址/Github |
| MeshDiffusion | MeshDiffusion 可以使用基于分数的扩散模型和可变形四面体网格来生成逼真的 3D 网格。它非常适合从单个图像创建详细的 3D 形状,还可以添加纹理,使其可用于各种应用程序。 | 项目地址/Github |
| Robust Dynamic Radiance Fields | 鲁棒动态辐射场可以估计静态和动态辐射场以及相机设置。它改进了困难视频的视图合成,实现了比当前顶级方法更好的质量和准确性。 | 项目地址/Github |
| 3D Neural Field Generation using Triplane Diffusion | 使用三平面扩散的 3D 神经场生成可以从 2D 图像创建高质量的 3D 模型。它使用扩散模型将 ShapeNet 网格转变为连续占用场,在各种对象类型的 3D 生成中取得了最佳结果。 | 项目地址/Github |
3D Segmentation
3D 分割
| 工具 | 简单说明 | 链接 |
|---|---|---|
| GeoSAM2 | GeoSAM2 可以使用 2D 提示将 3D 网格分割成多个部分。 | 项目地址/Github |
| ObjectCarver | ObjectCarver 只需用户输入点击即可从单个视图中分割、重建和分离 3D 对象,从而无需分割蒙版。 | 项目地址/Github |
| PARTFIELD | PartField 可以将 3D 形状分割成多个部分,而无需使用模板或文本名称。 | 项目地址/Github |
| HoloPart | HoloPart 可以将 3D 形状分解为完整且有意义的部分,即使它们是隐藏的。它还支持众多下游应用程序,例如几何编辑、几何处理、材质编辑和动画。 | 项目地址/Github |
| Find Any Part in 3D | Find3D 可以根据文本查询分割 3D 对象的各个部分。 | 项目地址/Github |
| GARField | GARField 可以将 3D 场景分解为有意义的组。它提高了对象聚类的准确性,并允许更好地提取单个对象及其部分。 | 项目地址/Github |
| LESS | One-2-3-45 可以在短短 45 秒内从单个图像生成完整的 360 度 3D 纹理网格。它使用视图条件的二维扩散模型来创建多个图像,从而比其他方法产生更好的几何形状和一致性。 | 项目地址/Github |
3D Style Transfer
3D 风格迁移
| 工具 | 简单说明 | 链接 |
|---|---|---|
| ReStyle3D | ReStyle3D 可以从不同角度将风格图像的外观转移到现实世界场景。它保持结构和细节完整,非常适合室内设计和虚拟舞台。 | 项目地址/Github |
| StyleSplat | StyleSplat 可以根据参考样式图像对由 3D 高斯表示的场景中的 3D 对象进行风格化。该方法能够将样式转移本地化到特定对象,并支持多种样式的风格化。 | 项目地址/Github |
| Generative Repainting | 生成重绘可以使用文本提示来绘制 3D 资源。它使用预训练的 2D 扩散模型和 3D 神经辐射场来为各种 3D 形状创建高质量纹理。 | 项目地址/Github |
| RecolorNeRF | RecolorNeRF 可以改变 3D 场景中的颜色,同时保持视图一致。它将场景分解为纯色图层,可以轻松进行颜色调整并产生比其他方法更好的逼真结果。 | 项目地址/Github |
| ARF | ARF:艺术辐射场可以通过风格化辐射场将 2D 图像的风格转移到 3D 场景。它捕捉风格细节,同时确保场景的不同视图看起来一致,从而产生与原始风格图像紧密匹配的高质量 3D 内容。 | 项目地址/Github |
3D Texture Generation
3D 纹理生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| IntrinsiX | IntrinsiX 可以根据文本描述生成高质量的 PBR 地图。它有助于重新照明、材质编辑和纹理生成,生成详细且连贯的图像。 | 项目地址/Github |
| MVPaint | MVPaint 可以为 3D 模型生成高分辨率、无缝纹理。它采用三阶段流程来提高纹理质量,包括多视图生成和 UV 细化以减少可见接缝。 | 项目地址/Github |
| Hunyuan3D 2.1 | Hunyuan3D 2.1可以通过形状生成和纹理合成从图像生成高质量的3D资产。 | Github |
| UniTEX | UniTEX 可以在不使用 UV 映射的情况下为 3D 资源生成高质量纹理。它根据表面接近度将 3D 点映射到纹理值,并使用基于转换器的模型来获得更好的纹理质量。 | Github |
| MVPainter | MVPainter 可以通过将参考纹理与几何体对齐来生成高质量的 3D 纹理。 | 项目地址/Github |
| TexGaussian | TexGaussian 可以一步生成用于 3D 网格的高质量 PBR 材质。它可以快速生成反照率、粗糙度和金属贴图,并具有出色的视觉质量,确保与输入几何体更好的一致性。 | 项目地址/Github |
| Hunyuan3D 2.0 | Hunyuan3D 2.0可以生成高分辨率纹理3D资源。它允许用户高效地创建详细的 3D 模型并为其制作动画,与以前的模型相比,几何细节和纹理质量得到了改进。 | 项目地址/Github |
| FabricDiffusion | FabricDiffusion 可以将高质量的织物纹理从 2D 服装图像转移到任何形状的 3D 服装。 | 项目地址/Github |
| TEXGen | TEXGen 可以使用 7 亿参数扩散模型在纹理空间中生成高分辨率 UV 纹理图。它支持文本引导的纹理修复和稀疏视图纹理完成,使其可用于为 3D 资源创建纹理。 | 项目地址/Github |
| PRM | PRM 可以使用光度立体技术从单个图像创建高质量的 3D 网格。它可以改善细节并处理照明和材质的变化,从而实现重新照明和材质编辑等功能。 | 项目地址/Github |
| Material Anything | 材质任何东西都可以为 3D 对象生成逼真的材质,包括那些没有纹理的材质。它适应不同的照明,并使用置信蒙版来提高材质质量,确保输出为 UV 映射做好准备。 | 项目地址/Github |
| SuperMat | SuperMat 可以快速将材质图像分解为三个重要的贴图:反照率、金属度和粗糙度。它在大约 3 秒内完成此操作,同时保持高质量,使其能够高效地进行 3D 对象材质估计。 | 项目地址/Github |
| Make-it-Real | Make-it-Real 可以使用 GPT-4V 识别和描述材料,帮助构建详细的材料库。它将材质与 3D 对象部分对齐,并从反照率贴图创建 SVBRDF 材质,从而提高 3D 资产的真实感。 | 项目地址/Github |
| InstructHumans | InstructHumans 可以使用文本提示编辑现有的 3D 人体纹理。它很好地保持了头像的一致性,并且可以轻松实现动画。 | 项目地址/Github |
| 3D Paintbrush | 3D Paintbrush 可以使用文本描述自动将纹理添加到 3D 模型上的特定区域。它可以生成详细的定位和纹理图,从而提高各种项目中的图形质量。 | 项目地址/Github |
| Generative Repainting | 生成重绘可以使用文本提示来绘制 3D 资源。它使用预训练的 2D 扩散模型和 3D 神经辐射场来为各种 3D 形状创建高质量纹理。 | 项目地址/Github |
| TEXTure | TEXTURE 可以使用文本提示生成和编辑 3D 形状的无缝纹理。它使用深度到图像扩散模型从不同角度创建一致的纹理,并允许根据用户输入进行细化。 | 项目地址/Github |
| TextureDreamer | TextureDreamer 可以将 3 到 5 个图像的详细纹理传输到任何 3D 形状。它使用一种称为几何感知分数蒸馏的方法来提高纹理质量,超越以前的技术。 | 项目地址/Github |
3D Virtual Try-On
3D 虚拟试穿
| 工具 | 简单说明 | 链接 |
|---|---|---|
| FabricDiffusion | FabricDiffusion 可以将高质量的织物纹理从 2D 服装图像转移到任何形状的 3D 服装。 | 项目地址/Github |
| StructLDM | StructLDM 可以通过混合不同的身体部位、身份交换、本地服装编辑、3D 虚拟试穿等来生成可动画的合成人体。人工智能女朋友/男朋友肯定会成为热门话题。 | 项目地址/Github |
3D Scene Generation-3D Object Generation
3D 场景生成-3D 物体生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| D-NPC | 赛博朋克脑舞正在成为一种潮流! D-NPC 可以将视频转换为动态神经点云(又名 4D 场景),从而可以从另一个角度观看场景。 | 项目地址/Github |
Audio-to-3D
音频转 3D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| MemoryTalker | MemoryTalker 可以仅从音频生成逼真的 3D 面部动画,无需说话者 ID 或 3D 面部网格。 | 项目地址/Github |
| DIDiffGes | DIDiffGes 只需 10 个采样步骤即可从语音生成高质量手势。 | 项目地址/Github |
| ProbTalk3D | ProbTalk3D 可以根据音频输入生成显示不同情绪的 3D 面部动画!它使用两阶段 VQ-VAE 模型和 3DMEAD 数据集,允许多样化的面部表情和准确的口型同步。 | 项目地址/Github |
| GeneFace | GeneFace 可以从任何语音音频生成高质量的 3D 人脸视频。它解决了头躯干分离问题,并提供比早期方法更好的唇形同步和图像质量。 | 项目地址/Github |
| Real3D-Portrait | Real3D-Portrait 是一种一次性 3D 说话肖像生成方法。它能够生成具有自然躯干运动和可切换背景的逼真视频。 | 项目地址/Github |
| From Audio to Photoreal Embodiment | Audio2Photoreal 可以生成全身逼真的化身,并根据二元交互的对话动态做出手势。给定语音音频,该模型能够输出个人多种可能的手势运动,包括面部、身体和手。结果是高度逼真的化身,可以表达手势中的关键细微差别,例如冷笑和傻笑。 | 项目地址/Github |
Audio-to-Motion
音频转动作
| 工具 | 简单说明 | 链接 |
|---|---|---|
| ARTalk | ARTalk 可以根据音频实时生成逼真的 3D 头部运动,包括唇形同步、眨眼和面部表情。 | 项目地址/Github |
| GestureLSM | GestureLSM 可以通过建模不同身体部位的交互方式来生成实时协同语音手势。 | 项目地址/Github |
Brain-to-3D
脑信号转 3D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| MinD-3D | MinD-3D 可以根据 fMRI 大脑信号重建高质量的 3D 对象。它使用三阶段框架来解码 3D 视觉信息,显示大脑处理和创建的对象之间的紧密联系。 | 项目地址/Github |
| DREAM | DREAM 可以使用功能磁共振成像到图像的方法重建人从大脑活动中看到的图像。它解码了颜色和深度等重要细节,并且在保持外观和结构一致方面比其他模型表现更好。 | 项目地址/Github |
Controllable 3D Generation
可控 3D 生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| SceneCraft | SceneCraft 可以根据用户布局和文本描述生成详细的室内 3D 场景。它能够将 3D 布局转换为 2D 地图,生成具有不同纹理和逼真视觉效果的复杂空间。 | 项目地址/Github |
| ThemeStation | ThemeStation 可以通过几个示例生成与特定主题相匹配的各种 3D 资源。它使用两阶段过程来提高模型的质量和多样性,允许用户根据自己的文本提示创建 3D 资产。 | 项目地址/Github |
Image-to-3D
图像转 3D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| StyleCity | StyleCity 可以以语义感知的方式对大型城市场景的 3D 纹理网格进行风格化,并生成和谐的全向天空背景。 | 项目地址/Github |
| MeshPad | MeshPad 可以从 2D 草图创建和编辑 3D 网格。用户可以通过简单的草图更改轻松添加或删除网格零件。 | 项目地址/Github |
| StyleSculptor | StyleSculptor 可以从内容图像和样式图像生成 3D 资源,无需额外培训。 | 项目地址/Github |
| Lyra | Lyra 可以从单个图像或视频生成 3D 场景。它使用一种允许实时渲染和动态场景生成的方法,无需多个视图进行训练。 | 项目地址/Github |
| Matrix-3D | Matrix-3D 可以根据单个图像或文本提示生成 3D 世界。它允许用户从任何方向探索这些环境,并支持快速和详细的场景创建。 | 项目地址/Github |
| Symmetry Strikes Back | Reflect3D 可以从单个 RGB 图像中检测 3D 反射对称性并改进 3D 生成。 | 项目地址/Github |
| PhysX | PhysX 可以生成具有详细物理属性的 3D 资产,在五个关键领域标记资产:规模、材料、可供性、运动学和功能。 | 项目地址/Github |
| PartPacker | PartPacker 可以从单个图像生成具有许多有意义的部分的高质量 3D 对象。 | 项目地址/Github |
| UniTEX | UniTEX 可以在不使用 UV 映射的情况下为 3D 资源生成高质量纹理。它根据表面接近度将 3D 点映射到纹理值,并使用基于转换器的模型来获得更好的纹理质量。 | Github |
| Direct3D-S2 | Direct3D-S2 可以生成高分辨率的 3D 形状。 | 项目地址/Github |
| 4K4DGen | 4K4DGen 可以将单个全景图像转变为具有 4K 分辨率的 360 度视图的沉浸式 4D 环境。该方法能够使用高效的泼溅技术对场景进行动画处理并优化一组 4D 高斯函数以进行实时探索。 | 项目地址/Github |
| SVAD | SVAD 可以从单个图像生成高质量的 3D 头像。它可以在不同姿势和角度下保持人物的身份和细节一致,同时允许实时渲染。 | 项目地址/Github |
| HORT | HORT 可以仅通过一张照片创建手持物体的详细 3D 点云。 | 项目地址/Github |
| LVSM | LVSM 可以从一些输入图像生成对象和场景的高质量 3D 视图。 | 项目地址/Github |
| DiffPortrait360 | DiffPortrait360 可以从单个图像创建高质量的 360 度人体头部视图。 | 项目地址/Github |
| MVGenMaster | MVGenMaster 可以使用多视图扩散模型从单个图像生成多达 100 个新视图。 | 项目地址/Github |
| StdGEN | StdGEN 可以在短短三分钟内从单个图像生成高质量的 3D 角色。它将角色分解为身体、衣服和头发等部分,使用基于 Transformer 的模型在 3D 动漫角色生成中取得良好的效果。 | 项目地址/Github |
| Phidias | Phidias 可以从文本、图像和 3D 参考生成高质量的 3D 资源。它使用一种称为参考增强扩散的方法来提高质量和速度,只需几秒钟即可获得结果。 | 项目地址/Github |
| Cycle3D | Cycle3D 可以从单个未摆姿势的图像生成高质量且一致的 3D 内容。这种方法增强了纹理一致性和多视图连贯性,显着提高了最终 3D 重建的质量。 | 项目地址/Github |
| DiffSplat | DiffSplat 可以在 1-2 秒内根据文本提示和单视图图像生成 3D 高斯图。 | 项目地址/Github |
| FabricDiffusion | FabricDiffusion 可以将高质量的织物纹理从 2D 服装图像转移到任何形状的 3D 服装。 | 项目地址/Github |
| Tactile DreamFusion | Tactile DreamFusion 可以通过将高分辨率触觉传感与基于扩散的图像先验相结合来改进 3D 资产生成。支持文本转 3D 和图像转 3D 生成。 | 项目地址/Github |
| Trellis 3D | Trellis 3D 可生成辐射场、3D 高斯和网格等格式的高质量 3D 资源。它支持文本和图像调节,提供灵活的输出格式选择和本地 3D 编辑功能。 | 项目地址/Github |
| Long-LRM | Long-LRM 可以在单个 A100 80G GPU 上仅 1.3 秒内从多达 32 个分辨率为 960x540 的输入图像重建大型 3D 场景。 | 项目地址/Github |
| DimensionX | DimensionX 可以使用可控视频扩散从单个图像生成逼真的 3D 和 4D 场景。 | 项目地址/Github |
| CRM | 感觉我们现在每周都会获得一种图像转 3D 方法。 CRM 是另一种可以从单个图像生成 3D 对象的软件。它能够在短短 10 秒内创建具有可交互表面的高保真纹理网格。结果令人惊叹! | 项目地址/Github |
| 3D-Fauna | 3D-Fauna 能够以前馈方式将四足动物的单个图像转换为铰接的、有纹理的 3D 网格,为动画和渲染做好准备。 | 项目地址/Github |
| WiLoR | WiLoR 可以根据单张图像实时定位和重建多只手。它使用包含超过 200 万张手部图像的大型数据集,实现高精度的平滑 3D 手部跟踪。 | 项目地址/Github |
| 3DTopia-XL | 3DTopia-XL 可以在短短 5 秒内从文本或图像输入生成高质量的 3D PBR 资源。 | 项目地址/Github |
| DrawingSpinUp | DrawingSpinUp 可以将单个 2D 绘图中的 3D 角色制作成动画。它删除了不必要的线条,并使用基于骨架的算法来允许角色旋转、跳跃和跳舞。 | 项目地址/Github |
| SparseCraft | SparseCraft 可以仅根据三张彩色图像重建 3D 形状和外观。它使用有符号距离函数 (SDF) 和辐射场,无需预训练模型即可实现 10 分钟以内的快速训练时间。 | 项目地址/Github |
| DreamCar | DreamCar 可以通过少量图像或单图像输入重建 3D 汽车模型。它使用分数蒸馏采样和姿势优化来增强纹理对齐和整体模型质量,显着优于现有方法。 | 项目地址/Github |
| An Object is Worth 64x64 Pixels | 一个对象值得 64x64 像素可以从 64x64 像素图像生成 3D 模型!它可以创建具有良好形状和颜色的逼真对象,以及更复杂的方法。 | 项目地址/Github |
| Tailor3D | Tailor3D 可以从文本或单面和双面图像创建自定义 3D 资源。该方法还支持通过附加文本提示添加对输入的更改。 | 项目地址/Github |
| Portrait3D | Portrait3D 可以从单个野外肖像图像生成具有精确几何形状和纹理的高质量 3D 头部。 | 项目地址/Github |
| Sketch2Scene | Sketch2Scene 可以从简单的草图和文本描述创建交互式 3D 游戏场景。它使用带有 ControlNet 的扩散模型和程序生成来制作符合用户需求的高质量、可玩的 3D 环境。 | 项目地址/Github |
| Toon3D | Toon3D 可以从两个或多个卡通图画生成 3D 场景。它远非完美,但仍然很酷! | 项目地址/Github |
| InstantMesh | InstantMesh 可以在 10 秒内从单个图像生成高质量的 3D 网格。它使用多视图扩散和稀疏视图重建等先进方法,在质量和速度上都明显优于其他工具。 | Github |
| MoCap-to-Visual Domain Adaptation for Efficient Human Mesh Estimation from 2D Keypoints | 说到重建。 Key2Mesh 是另一个进行 3D 人体网格重建的模型,这次利用 2D 人体姿势关键点作为输入,而不是由于带有 3D 标签的图像数据集的稀缺而依赖视觉数据。 | 项目地址/Github |
| TexDreamer | TexDreamer 可以从文本和图像生成高质量的 3D 人体纹理。它使用智能微调方法和独特的翻译模块来快速创建逼真的纹理,同时保持重要细节完整。 | 项目地址/Github |
| TripoSR | TripoSR 可以在 0.5 秒内从单个图像生成高质量的 3D 网格。 | Github |
| MeshFormer | MeshFormer 可以在几秒钟内从几个 2D 图像生成高质量的 3D 纹理网格。 | 项目地址/Github |
| LGM | LGM 可以根据文本提示或单视图图像生成高分辨率 3D 模型。它使用快速多视图高斯表示,在 5 秒内生成模型,同时保持高质量。 | 项目地址/Github |
| En3D | En3D 可以从 2D 图像生成高质量的 3D 人体头像,而无需现有资产。 | 项目地址/Github |
| Doodle Your 3D | Doodle Your 3D 可以将抽象草图变成精确的 3D 形状。该方法甚至可以通过简单地编辑草图来编辑形状。超级酷。从草图到 3D 打印现在并不遥远。 | 项目地址/Github |
| WonderJourney | WonderJourney 让您漫步在您最喜爱的绘画、诗歌和俳句中。该方法可以从单个图像或文本提示生成一系列不同但连贯连接的 3D 场景。 | 项目地址/Github |
| ZeroNVS | ZeroNVS 是一种 3D 感知扩散模型,能够从单个真实图像生成野外场景的新颖 360 度视图。 | 项目地址/Github |
| Zero123++ | Zero123++ 可以使用图像条件扩散模型从单个输入图像生成高质量、3D 一致的多视图图像。它修复了模糊纹理和未对齐形状等常见问题,并包含 ControlNet,以便更好地控制图像创建过程。 | Github |
| Wonder3D | Wonder3D 能够将单个图像转换为高保真 3D 模型,并带有纹理网格和颜色。整个过程仅需2至3分钟。 | 项目地址/Github |
| DreamGaussian | DreamGaussian 可以在短短 2 分钟内从单视图图像生成高质量的纹理网格。它使用 3D 高斯泼溅模型进行快速网格提取和纹理细化。 | 项目地址/Github |
| PlankAssembly | PlankAssembly 可以将 2D 线图从三个视图转换为 3D CAD 模型。它可以有效地处理嘈杂或不完整的输入,并使用形状程序提高准确性。 | 项目地址/Github |
| SketchMetaFace | 与 ControlNet 图像涂鸦类似,SketchMetaFace 将草图指导带入 3D 领域,并使将草图转换为 3D 面部模型成为可能。我们对这样的进展感到非常兴奋,因为这将为 3D 生成带来可控性,并使生成 3D 内容变得更容易。 | 项目地址/Github |
| PAniC-3D | PANiC-3D 可以从单视图动漫肖像中重建 3D 角色头部。它使用线填充模型和体积辐射场,取得了比以前的方法更好的结果,并为风格化重建树立了新标准。 | Github |
| Make-It-3D | Make-It-3D 可以通过估计 3D 形状并添加纹理,从单个图像创建高质量的 3D 内容。它使用经过训练的 2D 扩散模型的两步过程,允许文本到 3D 创建和详细的纹理编辑。 | 项目地址/Github |
| SceneDreamer | SceneDreamer 可以从 2D 图像集合生成无尽的 3D 场景。它可以创建具有清晰深度的逼真图像,并允许相机在环境中自由移动。 | 项目地址/Github |
| EVA3D | EVA3D 可以从 2D 图像集合生成高质量的 3D 人体模型。它使用一种称为组合 NeRF 的方法来处理详细的形状和纹理,并通过姿势引导采样来改进学习。 | Github |
| LRM | Adobe 正在进军图像转 3D 游戏。 LRM 可以在短短 5 秒内从单个图像创建高保真 3D 对象网格。该模型接受了包含约 100 万个对象的海量多视图数据的训练。结果非常令人印象深刻,并且该方法能够很好地推广到生成模型中的现实世界图片和图像。 | 项目地址/Github |
Image-to-4D
图像转 4D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| DreamGaussian4D | DreamGaussian4D 可以从单个图像生成动画 3D 网格。该方法能够为同一静态模型生成不同的运动,并且与其他方法相比,只需 4.5 分钟而不是几个小时。 | 项目地址/Github |
| Splatter Image | Splatter Image 可以以每秒 38 帧的速度从单个图像重建 4D 视频,并以每秒 588 帧的速度渲染它们。 | 项目地址/Github |
Image-to-Texture
图像转纹理
| 工具 | 简单说明 | 链接 |
|---|---|---|
| UniTEX | UniTEX 可以在不使用 UV 映射的情况下为 3D 资源生成高质量纹理。它根据表面接近度将 3D 点映射到纹理值,并使用基于转换器的模型来获得更好的纹理质量。 | Github |
| MVPainter | MVPainter 可以通过将参考纹理与几何体对齐来生成高质量的 3D 纹理。 | 项目地址/Github |
| SuperMat | SuperMat 可以快速将材质图像分解为三个重要的贴图:反照率、金属度和粗糙度。它在大约 3 秒内完成此操作,同时保持高质量,使其能够高效地进行 3D 对象材质估计。 | 项目地址/Github |
| StyleGaussian | 另一方面,StyleGaussian 能够以 10fps 的速度将任何图像的风格即时转换为 3D 场景,同时保持严格的多视图一致性。 | 项目地址/Github |
| Mesh Neural Cellular Automata | 网格神经元胞自动机 (MeshNCA) 是一种在 3D 网格上直接合成动态纹理的方法,无需任何 UV 贴图。该模型可以使用不同的目标进行训练,例如图像、文本提示和运动矢量场。此外,MeshNCA 允许多种用户交互,包括纹理密度/方向控制、嫁接画笔和运动速度/方向控制。 | 项目地址/Github |
Motion Capture
动作捕捉
| 工具 | 简单说明 | 链接 |
|---|---|---|
| GlobalPose | GlobalPose 可以使用 6 个 IMU(惯性测量单元)捕捉 3D 空间中的人体运动。它可以准确地重建全局运动和局部姿态,同时估计 3D 接触和力。 | 项目地址/Github |
| CoMotion | CoMotion 仅使用一台摄像头即可检测和跟踪多人的 3D 姿势。它在拥挤的地方运行良好,并且可以高精度地跟踪一段时间内的运动情况。 | Github |
| LHM | LHM 可以在几秒钟内从单个图像生成高质量、可动画的 3D 人体头像。它保留了服装几何形状和纹理等细节,无需对面部和手部进行额外处理。 | 项目地址/Github |
| EgoAllo | EgoAllo 可以使用头戴式设备的图像来估计 3D 人体姿势、高度和手部参数。 | 项目地址/Github |
| SpatialTracker | SpatialTracker 可以跟踪 3D 空间中的 2D 像素,即使对象被阻挡或旋转也是如此。它使用深度估计器和三平面表示来在困难的情况下实现最佳性能。 | 项目地址/Github |
| AiOS | AiOS可以一步估计人体姿势和形状,结合身体、手部和面部表情恢复。 | 项目地址/Github |
| Humans in 4D | [Humans in 4D] 可以通过单个视频以 3D 形式跟踪和重建人类。它可以很好地处理不寻常的姿势和较差的可见性,使用名为 HMR 2.0 的基于变压器的网络来改进动作识别。 | 项目地址/Github |
Motion Editing
动作编辑
| 工具 | 简单说明 | 链接 |
|---|---|---|
| MotionLab | MotionLab可以生成和编辑人体动作,并支持基于文本和基于轨迹的动作创建。 | 项目地址/Github |
Motion Generation
动作生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| Sketch2Anim | Sketch2Anim 可以将 2D 故事板草图转换为高质量的 3D 动画。它使用运动生成器进行精确控制,并使用神经映射器将 2D 草图与 3D 运动对齐,从而轻松进行编辑和动画控制。 | 项目地址/Github |
| ControlMM | ControlMM 可以通过在运动模型中使用空间控制信号来实时生成高质量的运动。它比其他方法快 20 倍,并且可以控制身体部位、时间线并避开障碍物。 | 项目地址/Github |
| TokenHSI | TokenHSI 可以使用基于变压器的统一策略,使基于物理的角色能够与其环境进行交互。它通过可变长度输入适应新情况,并改善跨任务的知识共享,使交互更加多样化。 | 项目地址/Github |
| InterMimic | InterMimic 可以从不完美的动作捕捉数据中学习复杂的人机交互。它可以对全身与动态对象的交互进行真实的模拟,并与运动生成器配合使用以实现更好的建模。 | 项目地址/Github |
| InterMask | InterMask 可以根据文本描述生成高质量的 3D 人类交互。它捕获两个人之间的复杂运动,同时还允许在不改变模型的情况下生成反应。 | 项目地址/Github |
| MotionLab | MotionLab可以生成和编辑人体动作,并支持基于文本和基于轨迹的动作创建。 | 项目地址/Github |
| SMF | SMF 可以将 2D 或 3D 关键点动画转换为全身网格动画,而无需模板网格或校正关键帧。 | 项目地址/Github |
| GestureLSM | GestureLSM 可以通过建模不同身体部位的交互方式来生成实时协同语音手势。 | 项目地址/Github |
| CLoSD | CLoSD 可以使用文本提示控制基于物理的模拟中的角色。它可以导航到目标、撞击物体以及在坐姿和站姿之间切换,所有这些都由简单的指令引导。 | 项目地址/Github |
| MaskedMimic | MaskedMimic 可以使用基于物理的控制器为交互式角色生成多种动作。它支持关键帧和文本等各种输入,可以平滑过渡并适应复杂的环境。 | 项目地址/Github |
| Flexible Motion In-betweening with Diffusion Models | CondMDI 可以生成精确且多样化的运动,符合灵活的用户指定的空间约束和文本描述。这样就可以仅根据文本提示和关键帧之间的修复来创建高质量的动画。 | 项目地址/Github |
| StableMoFusion | StableMoFusion 是一种人体运动生成方法,能够消除脚滑并创建稳定高效的动画。该方法基于扩散模型,可用于虚拟角色和人形机器人等实时场景。 | 项目地址/Github |
| PhysDreamer | PhysDreamer 是一种基于物理的方法,使您能够在虚拟 3D 环境中戳、推、拉和投掷物体,它们会以物理上合理的方式做出反应。 | 项目地址/Github |
| Towards Variable and Coordinated Holistic Co-Speech Motion Generation | ProbTalk 是一种为 3D 化身生成逼真的整体语音动作的方法。该方法能够产生各种动作,并确保面部表情、手势和身体姿势之间的和谐一致。 | 项目地址/Github |
| Synthesizing Physically Plausible Human Motions in 3D Scenes | InterScene 是一个新颖的框架,使物理模拟的角色能够在多样化、杂乱和看不见的场景中执行长期交互任务。距离完全动态的游戏世界和模拟又近了一步。查看下面令人印象深刻的演示。 | 项目地址/Github |
| RoHM | RoHM 可以从单眼视频重建完整、可信的 3D 人体运动,并支持识别闭塞的关节!因此,基本上是类固醇的运动跟踪,但不需要昂贵的设置。 | 项目地址/Github |
| MotionGPT | MotionGPT 可以像语言一样生成、描述和预测人体运动。它在这些任务中实现了顶级性能,使其可用于各种与运动相关的应用。 | 项目地址/Github |
| Human Motion Diffusion as a Generative Prior | PriorMDM 可以使用预先训练的扩散模型生成长达 10 分钟的人体运动序列。它允许在提示间隔之间进行受控过渡,并且只需 14 个训练示例即可创建两人动作,并使用 DiffusionBlending 等技术来实现更好的控制。 | 项目地址/Github |
| Temporal Residual Jacobians For Rig-free Motion Transfer | [时间残差雅可比行列式] 可以将运动从一个 3D 网格转移到另一个 3D 网格,而无需装配或形状关键帧。它使用两个神经网络来预测变化,允许在不同体型之间进行真实的运动转移。 | 项目地址/Github |
Sketch-to-3D
草图转 3D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| S3D | S3D 可以从简单的手绘草图生成 3D 模型。 | Github |
Text-to-3D
文本转 3D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| StyleCity | StyleCity 可以以语义感知的方式对大型城市场景的 3D 纹理网格进行风格化,并生成和谐的全向天空背景。 | 项目地址/Github |
| Lyra | Lyra 可以从单个图像或视频生成 3D 场景。它使用一种允许实时渲染和动态场景生成的方法,无需多个视图进行训练。 | 项目地址/Github |
| MaPa | MaPa 可以生成高质量的 3D 网格材质!它可以创建分段程序材质图作为外观表示,支持高质量渲染并提供显着的编辑灵活性。 | 项目地址/Github |
| Matrix-3D | Matrix-3D 可以根据单个图像或文本提示生成 3D 世界。它允许用户从任何方向探索这些环境,并支持快速和详细的场景创建。 | 项目地址/Github |
| Event-Driven Storytelling | 事件驱动的叙事可以为 3D 场景中的多个角色生成逼真的动作。它使用大型语言模型来理解复杂的交互,从而允许基于角色关系及其位置进行多样化且可扩展的行为规划。 | 项目地址/Github |
| PhysX | PhysX 可以生成具有详细物理属性的 3D 资产,在五个关键领域标记资产:规模、材料、可供性、运动学和功能。 | 项目地址/Github |
| LayoutVLM | LayoutVLM 可以根据文本指令生成 3D 布局。它提高了布局与预期设计的匹配程度,并在拥挤的空间中有效地工作。 | 项目地址/Github |
| SceneFactor | SceneFactor 使用中间 3D 语义图从文本生成 3D 场景。可以编辑该贴图以添加、删除、调整大小和替换对象,从而轻松重新生成最终 3D 场景。 | 项目地址/Github |
| Phidias | Phidias 可以从文本、图像和 3D 参考生成高质量的 3D 资源。它使用一种称为参考增强扩散的方法来提高质量和速度,只需几秒钟即可获得结果。 | 项目地址/Github |
| LayerPano3D | LayerPano3D 可以通过将 2D 全景图分解为深度图层,根据单个文本提示生成身临其境的 3D 场景。 | 项目地址/Github |
| DiffSplat | DiffSplat 可以在 1-2 秒内根据文本提示和单视图图像生成 3D 高斯图。 | 项目地址/Github |
| GaussianDreamerPro | GaussianDreamerPro 可以从文本生成 3D 高斯资产,这些资产可以无缝集成到下游操作管道中,例如动画、合成和模拟。 | 项目地址/Github |
| YouDream | YouDream 可以从单个图像和文本提示生成高质量的 3D 动物。该方法能够保持解剖学的一致性,并且能够生成和组合常见的动物。 | 项目地址/Github |
| Tactile DreamFusion | Tactile DreamFusion 可以通过将高分辨率触觉传感与基于扩散的图像先验相结合来改进 3D 资产生成。支持文本转 3D 和图像转 3D 生成。 | 项目地址/Github |
| Trellis 3D | Trellis 3D 可生成辐射场、3D 高斯和网格等格式的高质量 3D 资源。它支持文本和图像调节,提供灵活的输出格式选择和本地 3D 编辑功能。 | 项目地址/Github |
| GarmentDreamer | GarmentDreamer 可以根据文本提示生成可穿戴、可模拟的 3D 服装网格。该方法能够生成各种几何和纹理细节,从而可以创建各种不同的服装。 | 项目地址/Github |
| HeadStudio | HeadStudio 是另一种文本转 3D 头像模型,可以生成可动画化的头部头像。该方法能够生成表情变形平滑、实时渲染的高保真头像。 | 项目地址/Github |
| DreamWaltz-G | DreamWaltz-G 可以从文本生成高质量的 3D 头像,并使用 SMPL-X 运动序列将其动画化。它通过骨架引导分数蒸馏提高了头像的一致性,对于人类视频重演和创建具有多个主题的场景非常有用。 | 项目地址/Github |
| AvatarGO | AvatarGO 可以从文本生成 4D 人机交互场景。它使用 LLM 引导的接触重定向来实现准确的空间关系,并通过对应感知运动优化确保流畅的动画。 | 项目地址/Github |
| 3DTopia-XL | 3DTopia-XL 可以在短短 5 秒内从文本或图像输入生成高质量的 3D PBR 资源。 | 项目地址/Github |
| SO-SMPL | 根据文本描述生成解开的服装头像可以通过分别建模人体和服装来创建高质量的 3D 头像。此方法提高了纹理和几何质量,并与文本提示很好地对齐,从而增强了虚拟试穿和角色动画。 | 项目地址/Github |
| DreamHOI | DreamHOI 可以通过设置蒙皮人体模型来根据文本描述与物体进行交互,从而生成逼真的 3D 人与物体交互 (HOI)。它使用文本到图像的扩散模型来创建多样化的交互,而不需要大型数据集。 | 项目地址/Github |
| Feature Splatting | 说到 Splats,Feature Splatting 可以使用文本提示来操纵 3D 场景中对象的外观和物理属性。 | 项目地址/Github |
| Tailor3D | Tailor3D 可以从文本或单面和双面图像创建自定义 3D 资源。该方法还支持通过附加文本提示添加对输入的更改。 | 项目地址/Github |
| E.T. the Exceptional Trajectories | DIRECTOR 可以从描述摄像机和角色之间的关系和同步的文本生成复杂的摄像机轨迹。 | 项目地址/Github |
| Director3D | Director3D 可以根据文本提示生成真实的 3D 场景和自适应摄像机轨迹。该方法能够生成像素对齐的 3D 高斯作为直接 3D 场景表示,以实现一致的去噪。 | 项目地址/Github |
| GradeADreamer | GradeADreamer 是另一种文本转 3D 方法。该产品能够仅使用单个 RTX 3090 GPU 生成高质量资源,总生成时间不到 30 分钟。 | Github |
| Dual3D | Dual3D 是另一种文本转 3D 方法,只需 1 分钟即可根据文本提示生成高质量的 3D 资源。 | 项目地址/Github |
| X-Oscar | X-Oscar可以根据文本提示生成高质量的3D头像。它对几何、纹理和动画采用分步流程,同时通过先进技术解决低质量和过饱和等问题。 | 项目地址/Github |
| GaussianCube | GaussianCube 是一种图像到 3D 模型,能够从多视图图像生成高质量的 3D 对象。该模型还使用 3D Gaussian Splatting,将非结构化表示转换为结构化体素网格,然后训练 3D 扩散模型来生成新对象。 | 项目地址/Github |
| Garment3DGen | Garment3DGen 可以对 2D 图像和 3D 网格服装的几何形状和纹理进行风格化!它们可以安装在参数化实体的顶部并进行模拟。可用于 VR 中的手工服装交互或将草图转换为 3D 服装。 | 项目地址/Github |
| TexDreamer | TexDreamer 可以从文本和图像生成高质量的 3D 人体纹理。它使用智能微调方法和独特的翻译模块来快速创建逼真的纹理,同时保持重要细节完整。 | 项目地址/Github |
| HoloDreamer | HoloDreamer 可以根据文本描述生成封闭的 3D 场景。它首先创建高质量的等距柱状全景图,然后使用 3D 高斯分布快速重建 3D 场景。 | 项目地址/Github |
| MVControl | 通过表面对齐高斯喷射进行可控文本到 3D 生成,可以根据文本提示创建高质量的 3D 内容。它在多视图扩散模型中使用边缘、深度、法线和涂鸦贴图,通过独特的混合引导方法增强 3D 形状。 | 项目地址/Github |
| ViewDiff | ViewDiff 是一种可以根据单个文本提示或单个姿势图像在真实环境中生成真实世界 3D 对象的高质量、多视图一致图像的方法。 | 项目地址/Github |
| MeshFormer | MeshFormer 可以在几秒钟内从几个 2D 图像生成高质量的 3D 纹理网格。 | 项目地址/Github |
| GALA3D | GALA3D是一种文本转3D方法,可以生成具有多个对象的复杂场景并控制它们的放置和交互。该方法使用大型语言模型生成初始布局描述,然后通过条件扩散优化 3D 场景,使其更加真实。 | 项目地址/Github |
| LGM | LGM 可以根据文本提示或单视图图像生成高分辨率 3D 模型。它使用快速多视图高斯表示,在 5 秒内生成模型,同时保持高质量。 | 项目地址/Github |
| AToM | AToM 是一个文本到网格框架,可以在不到一秒的时间内根据文本提示生成高质量的纹理 3D 网格。该方法针对多个提示进行了优化,并且能够创建未经训练的各种对象。 | 项目地址/Github |
| Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation | 运动跟踪是一回事,从文本生成运动是另一回事。 STMC 是一种可以通过多轨时间线控制从文本生成 3D 人体运动的方法。这意味着用户可以指定具有定义的持续时间和重叠的多个提示的时间线,而不是单个文本提示,以创建更复杂和精确的动画。 | 项目地址/Github |
| En3D | En3D 可以从 2D 图像生成高质量的 3D 人体头像,而无需现有资产。 | 项目地址/Github |
| WonderJourney | WonderJourney 让您漫步在您最喜爱的绘画、诗歌和俳句中。该方法可以从单个图像或文本提示生成一系列不同但连贯连接的 3D 场景。 | 项目地址/Github |
| 4D-fy | 4D-fy可以根据文本提示生成高质量的4D场景。它结合了文本到图像和文本到视频模型的优势,创建具有出色视觉质量和逼真运动的动态场景。 | 项目地址/Github |
| LucidDreamer | LucidDreamer 是一个文本到 3D 生成框架,能够生成具有高质量纹理和形状的 3D 模型。更高的质量意味着更长的推理时间。该任务在 A100 GPU 上需要 35 分钟。 | Github |
| Progressive3D | Progressive3D 可以通过将过程分解为更小的编辑步骤,根据复杂的提示生成详细的 3D 内容。它让用户专注于特定区域进行编辑,并通过突出显示含义差异来改进结果。 | 项目地址/Github |
| HumanNorm | HumanNorm 是一种通过利用法线贴图来生成高质量和逼真的 3D 人体的新颖方法,可增强 3D 几何的 2D 感知。结果相当令人印象深刻,可与 PS3 游戏相媲美。 | 项目地址/Github |
| TECA | TECA 可以根据文本描述生成逼真的 3D 头像。它将面部和身体的传统 3D 网格与头发和衣服的神经辐射场 (NeRF) 相结合,从而实现高质量、可编辑的化身以及它们之间的轻松特征传输。 | 项目地址/Github |
| Text2NeRF | Text2NeRF 可以通过将神经辐射场 (NeRF) 与文本到图像扩散模型相结合,从文本描述生成 3D 场景。它无需额外的训练数据即可创建高质量的纹理和详细形状,从而比其他方法实现更好的照片真实感和多视图一致性。 | 项目地址/Github |
| LDM3D | DragonDiffusion 可以通过移动、调整大小和更改对象的外观来编辑图像,而无需重新训练模型。它允许用户在图像上拖动点,以便轻松、精确地进行编辑。 | Github |
| Shap-E | Shap-E 可以通过为隐式函数生成参数来生成复杂的 3D 资产。它可以创建纹理网格和神经辐射场,并且比 Point-E 模型运行速度更快、质量更好。 | 项目地址/Github |
| AvatarCraft | AvatarCraft 可以将文本提示变成高质量的 3D 人体头像。它允许用户控制头像的形状和姿势,无需重新训练即可轻松制作动画和重塑形状。 | 项目地址/Github |
| Let 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation | 3DFuse 可以通过向 2D 扩散模型添加 3D 感知来改进 3D 场景生成。它根据文本提示构建粗略的 3D 结构,并使用深度图在重建中获得更好的真实感。 | 项目地址/Github |
| Point-E | Point-E 可以在单个 GPU 上根据文本提示在 1-2 分钟内生成 3D 点云。它使用文本到图像扩散模型来创建视图,然后使用第二个扩散模型来生成点云,从而为 3D 对象生成提供更快的选项。 | Github |
| Latent-NeRF for Shape-Guided Generation of 3D Shapes and Textures | Latent-NeRF 可以通过结合文本和形状指导来生成 3D 形状和纹理。它使用潜在分数蒸馏将此指导直接应用于 3D 网格,从而在特定几何形状上实现高质量纹理。 | Github |
| InseRF | 尽管 Gaussian Splats 受到了很多人的喜爱,但 NeRF 并没有被放弃。本周我们收到了三篇不同的 NeRF 编辑论文。前两个是关于修复的。 InseRF和GO-NeRF都是将3D对象插入NeRF场景的方法。 | 项目地址/Github |
Text-to-4D
文本转 4D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| TC4D | TC4D 可以沿着任意轨迹对文本生成的 3D 场景进行动画处理。我发现这对于为电影或游戏生成 3D 效果非常有用。 | 项目地址/Github |
Text-to-Motion
文本转动作
| 工具 | 简单说明 | 链接 |
|---|---|---|
| GENMO | GENMO 可以根据文本、音频、视频和 3D 关键帧生成和估计人体运动。它允许灵活控制运动输出。 | 项目地址/Github |
| PINO | 通过将复杂的动作分解为简单的成对运动,PINO 可以在任何规模的群体之间生成真实的交互。它使用预训练的扩散模型进行两人交互,并通过基于物理的规则确保真实的运动,从而允许控制角色的速度和位置。 | 项目地址/Github |
| HOIDiNi | HOIDiNi 可以根据文本提示通过准确的手部接触和自然的身体运动来生成逼真的人机交互。 | 项目地址/Github |
| Human-Object Interaction from Human-Level Instructions | HOIFH 生成同步对象运动、全身人体运动和详细的手指运动。它设计用于在人类指令的指导下在上下文环境中操纵大型物体。 | 项目地址/Github |
| ControlMM | ControlMM 可以通过在运动模型中使用空间控制信号来实时生成高质量的运动。它比其他方法快 20 倍,并且可以控制身体部位、时间线并避开障碍物。 | 项目地址/Github |
| AnyTop | AnyTop 可以仅使用不同角色的骨骼结构来生成不同角色的动作。 | 项目地址/Github |
| Dance Like a Chicken | LoRA-MDM 可以通过使用一些带有运动扩散模型的参考样本来生成不同风格的程式化人体运动,例如“鸡”。它允许风格混合和动作编辑,同时在文本保真度和风格一致性之间保持良好的平衡。 | 项目地址/Github |
| MotionStreamer | MotionStreamer可以根据文本提示生成人体动作,并支持动作合成和较长的动作生成。还有一个 Blender 插件。 | 项目地址/Github |
| DART | DART 可以实时生成高质量的人体动作,在单个 RTX 4090 GPU 上实现每秒超过 300 帧。它将文本输入与空间约束相结合,允许执行诸如到达航路点和与场景交互等任务。 | 项目地址/Github |
| Dora | Dora 可以从图像生成 3D 资源,这些资源可以在现代 3D 引擎(例如 Unity 3D)中实时进行基于扩散的角色控制。 | 项目地址/Github |
| Generating Human Interaction Motions in Scenes with Text Control | TeSMo 是一种文本控制的场景感知运动生成方法,能够在具有各种对象形状、方向、初始身体位置和姿势的不同场景中生成逼真且多样化的人机交互,例如导航和坐姿。 | 项目地址/Github |
| MotionLab | MotionLab可以生成和编辑人体动作,并支持基于文本和基于轨迹的动作创建。 | 项目地址/Github |
| MoRAG – Multi-Fusion Retrieval Augmented Generation for Human Motion | MoRAG 可以通过改进运动扩散模型从文本中生成和检索人体运动。 | 项目地址/Github |
| CLoSD | CLoSD 可以使用文本提示控制基于物理的模拟中的角色。它可以导航到目标、撞击物体以及在坐姿和站姿之间切换,所有这些都由简单的指令引导。 | 项目地址/Github |
| Trans4D | Trans4D 可以生成具有表现力的对象变形的逼真 4D 场景过渡。 | Github |
| UniMuMo | UniMuMo 可以生成文本、音乐和动作的输出。它通过根据节奏模式对齐不配对的音乐和运动数据来实现这一点。 | 项目地址/Github |
| SynTalker | SynTalker 可以生成与语音和文本提示相匹配的逼真全身动作。它可以精确控制动作,比如走路时说话。 | 项目地址/Github |
| MaskedMimic | MaskedMimic 可以使用基于物理的控制器为交互式角色生成多种动作。它支持关键帧和文本等各种输入,可以平滑过渡并适应复杂的环境。 | 项目地址/Github |
| TSTMotion | TSTMotion 可以根据文本提示生成了解周围 3D 场景的人体运动序列。 | 项目地址/Github |
| LogoMotion | LogoMotion 可以将分层 PDF 文件中的徽标转换为内容感知的动画 HTML 画布动画。非常酷! | 项目地址/Github |
| SMooDi | SMooDi 可以根据文本提示和样式动作序列生成样式化动作。 | 项目地址/Github |
| E.T. the Exceptional Trajectories | DIRECTOR 可以从描述摄像机和角色之间的关系和同步的文本生成复杂的摄像机轨迹。 | 项目地址/Github |
| MagicPose4D | MagicPose4D 可以从文本或图像生成 3D 对象,并从视频或网格序列中的对象和角色传输精确的运动和轨迹。 | 项目地址/Github |
| Flexible Motion In-betweening with Diffusion Models | CondMDI 可以生成精确且多样化的运动,符合灵活的用户指定的空间约束和文本描述。这样就可以仅根据文本提示和关键帧之间的修复来创建高质量的动画。 | 项目地址/Github |
| in2IN | in2IN 是一种动作生成模型,它考虑了整体交互的文本描述和每个相关人员的个人动作描述。这增强了动作多样性,并能够更好地控制每个人的动作,同时保持交互连贯性。 | 项目地址/Github |
| Towards Variable and Coordinated Holistic Co-Speech Motion Generation | ProbTalk 是一种为 3D 化身生成逼真的整体语音动作的方法。该方法能够产生各种动作,并确保面部表情、手势和身体姿势之间的和谐一致。 | 项目地址/Github |
| Semantics2Hands | Semantics2Hands 可以在不同化身之间重新定位真实的手部动作,同时保留动作的细节。它使用基于解剖学的语义矩阵和语义重建网络来实现高质量的手部运动传输。 | 项目地址/Github |
| MotionGPT | MotionGPT 可以像语言一样生成、描述和预测人体运动。它在这些任务中实现了顶级性能,使其可用于各种与运动相关的应用。 | 项目地址/Github |
| Human Motion Diffusion as a Generative Prior | PriorMDM 可以使用预先训练的扩散模型生成长达 10 分钟的人体运动序列。它允许在提示间隔之间进行受控过渡,并且只需 14 个训练示例即可创建两人动作,并使用 DiffusionBlending 等技术来实现更好的控制。 | 项目地址/Github |
Text-to-Texture 3D Object Generation
文本转纹理、3D 物体生成
| 工具 | 简单说明 | 链接 |
|---|---|---|
| Make-It-Vivid | Make-It-Vivid 根据文本指令为 3D Biped 卡通人物生成高质量的纹理贴图,从而可以根据提示为角色设计服装和动画。 | 项目地址/Github |
Text-to-Texture
文本转纹理
| 工具 | 简单说明 | 链接 |
|---|---|---|
| InTeX | InTeX 可以实现交互式文本到纹理合成,以创建 3D 内容。它允许用户重新绘制特定区域并精确编辑纹理,而深度感知修复模型可减少 3D 不一致并加快生成速度。 | 项目地址/Github |
| FlashTex | FlashTex](https://flashtex.github.io) 可以根据用户提供的文本提示对输入 3D 网格进行纹理处理。这些生成的纹理也可以在不同的照明环境下正确重新照亮。 | 项目地址/Github |
| Paint-it | Paint-it 可以根据文本描述为 3D 网格生成高保真基于物理的渲染 (PBR) 纹理图。该方法能够通过改变高动态范围(HDR)环境照明来重新照亮网格,并在测试时控制材料属性。 | 项目地址/Github |
| Mesh Neural Cellular Automata | 网格神经元胞自动机 (MeshNCA) 是一种在 3D 网格上直接合成动态纹理的方法,无需任何 UV 贴图。该模型可以使用不同的目标进行训练,例如图像、文本提示和运动矢量场。此外,MeshNCA 允许多种用户交互,包括纹理密度/方向控制、嫁接画笔和运动速度/方向控制。 | 项目地址/Github |
Video-to-3D
视频转 3D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| Lyra | Lyra 可以从单个图像或视频生成 3D 场景。它使用一种允许实时渲染和动态场景生成的方法,无需多个视图进行训练。 | 项目地址/Github |
| VideoScene | VideoScene 可以一步从稀疏视频视图生成 3D 场景。 | 项目地址/Github |
| MegaSaM | MEGASAM 可以从休闲单目视频中估计相机参数和深度图。 | 项目地址/Github |
| WiLoR | WiLoR 可以根据单张图像实时定位和重建多只手。它使用包含超过 200 万张手部图像的大型数据集,实现高精度的平滑 3D 手部跟踪。 | 项目地址/Github |
| MeshAvatar | MeshAvatar 可以从多视图视频中生成高质量的三角形人体头像。化身可以被编辑、操纵和重新点燃。 | 项目地址/Github |
| XHand | XHand 可以实时生成高保真手部形状和纹理,为虚拟环境提供富有表现力的手部头像。 | 项目地址/Github |
| DreamScene4D | DreamScene4D 可以从单个视频生成动态 4D 场景。它跟踪对象运动并处理复杂的运动,通过将 3D 路径转换为 2D 来实现精确的 2D 点跟踪。 | 项目地址/Github |
| Dynamic Gaussians Mesh | DG-Mesh 能够从单个视频重建高质量且时间一致的 3D 网格。该方法还能够随着时间的推移跟踪网格顶点,从而能够对动态对象进行纹理编辑。 | 项目地址/Github |
| MonoHair | MonoHair 可以从单个视频创建高质量的 3D 头发。它采用两步过程进行详细的头发重建,并在各种发型中实现最佳性能。 | 项目地址/Github |
| Relightable and Animatable Neural Avatars from Videos | RelightableAvatar 是另一种可以从单眼视频创建可重新照明且可动画化的神经化身的方法。 | 项目地址/Github |
Video-to-4D
视频转 4D
| 工具 | 简单说明 | 链接 |
|---|---|---|
| 4K4DGen | 4K4DGen 可以将单个全景图像转变为具有 4K 分辨率的 360 度视图的沉浸式 4D 环境。该方法能够使用高效的泼溅技术对场景进行动画处理并优化一组 4D 高斯函数以进行实时探索。 | 项目地址/Github |
| CAT4D | CAT4D 可以从单个视频创建动态 4D 场景。它使用多视图视频扩散模型生成不同角度的视频,从而实现强大的 4D 重建和高质量图像。 | 项目地址/Github |
| MonST3R | MonST3R 可以随着时间的推移从视频中估计 3D 形状,创建动态点云并跟踪摄像机位置。与以前的技术相比,该方法改进了视频深度估计并更有效地将移动对象与静止对象分开。 | 项目地址/Github |
| SV4D 2.0 | SV4D 2.0可以从参考视频生成高质量的4D模型和视频。 | 项目地址/Github |
| SV4D | SV4D 可以从单个视频生成动态 3D 内容。它确保新视图在多个帧之间保持一致,并在视频合成中实现高质量的结果。 | 项目地址/Github |
| Video2Game | Video2Game 可以将现实世界的视频变成交互式游戏环境。它使用神经辐射场 (NeRF) 模块来捕获场景,使用网格模块来加快渲染速度,并使用物理模块来实现真实的对象交互。 | 项目地址/Github |
| DreamGaussian4D | DreamGaussian4D 可以从单个图像生成动画 3D 网格。该方法能够为同一静态模型生成不同的运动,并且与其他方法相比,只需 4.5 分钟而不是几个小时。 | 项目地址/Github |
| Consistent4D | Consolidated4D 是一种从未校准的单目视频生成 4D 动态对象的方法。随着我们的进展速度,单摄像头视频的动态 3D 场景似乎将比我过去几周的预期更快出现。 | 项目地址/Github |
Video-to-Motion
视频转动作
| 工具 | 简单说明 | 链接 |
|---|---|---|
| GENMO | GENMO 可以根据文本、音频、视频和 3D 关键帧生成和估计人体运动。它允许灵活控制运动输出。 | 项目地址/Github |

评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果